GTC 2010 Day 1: NVIDIA Announces Future GPU Families for 2011 And 2013
by Ryan Smith on September 22, 2010 2:46 AM ESTAs we mentioned last week, we’re currently down in San Jose, California covering NVIDIA’s annual GPU Technology Conference. If Intel has IDF and Apple has the World Wide Developers Conference, then GTC is NVIDIA’s annual powwow to rally their developers and discuss their forthcoming plans. The comparison to WWDC is particularly apt, as GTC is a professional conference focused on development and business use of the compute capabilities of NVIDIA’s GPUs (e.g. the Tesla market).
NVIDIA has been pushing GPUs as computing devices for a few years now, as they see it as the next avenue of significant growth for the company. GTC is fairly young – the show emerged from NVISION and its first official year was just last year – but it’s clear that NVIDIA’s GPU compute efforts are gaining steam. The number of talks and the number of vendors at GTC is up compared to last year, and according to NVIDIA’s numbers, so is the number of registered developers.

We’ll be here for the next two days meeting with NVIDIA and other companies and checking out the show floor. Much of this trip is to get a better grasp on just where things are for NVIDIA still-fledging GPU compute efforts, especially on the consumer front where GPU compute usage has been much flatter than we were hoping for at this time last year with the announcement/release of NVIDIA and AMD’s next-generation GPUs, and the ancillary launch of APIs such as DirectCompute and OpenCL, which are intended to allow developers to write an application against these common APIs rather than targeting CUDA or Brook+/Stream. If nothing else, we’re hoping to see where our own efforts in covering GPU computing need to lie – we want to add more compute tests to our GPU benchmarks, but is the market to the point yet where there’s going to be significant GPU compute usage in consumer applications? This is what we’ll be finding out over the next two days.
Jen-Hsun Huang Announces NVIDIA’s Next Two GPUs
While we’re only going to be on the show floor Wednesday and Thursday, GTC unofficially kicked off Monday, and the first official day of the show was Tuesday. Tuesday started off with a 2 hour keynote speech by NVIDIA’s CEO Jen-Hsun Huang, which keeping with the theme of GTC focused on the use of NVIDIA GPUs in business environments.
Not unlike GTC 2009, NVIDIA is also using the show as a chance to announce their next-generation GPUs. GTC 2009 saw the announcement of the Fermi family, with NVIDIA first releasing the details of the GPU’s compute capabilities there, before moving on to focusing on gaming at CES 2010. This year NVIDIA announced the next two GPU families the company is working on, albeit not in as much detail as we got about Fermi in 2009.
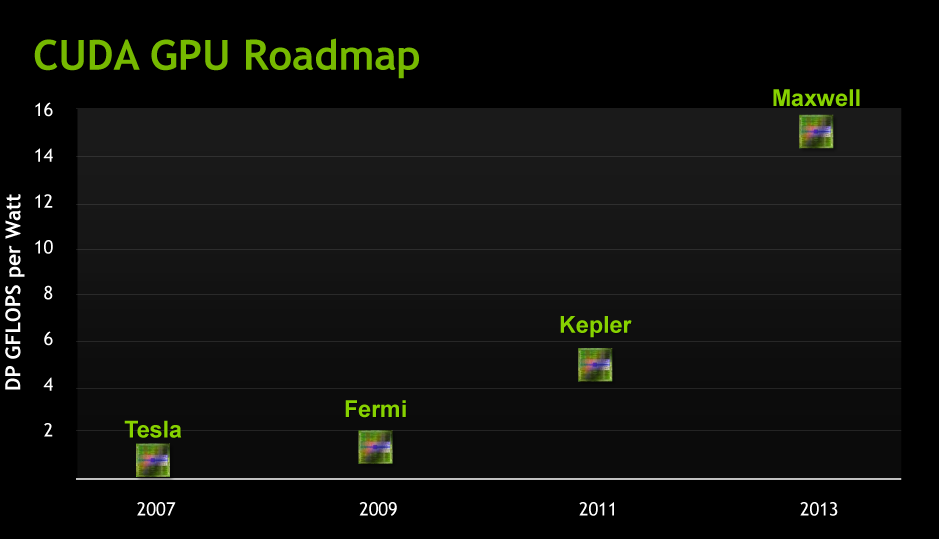
The progression of NVIDIA's GPUs from a Tesla/Compute Standpoint
The first GPU is called Kepler (as in Johannes Kepler the mathematician), which will be released in the 2nd half of 2011. At this point the GPU is still a good year out, which is why NVIDIA is not talking about its details just yet. For now they’re merely talking about performance in an abstract manner, in this case Kepler should offer 3-4 times the amount of double precision floating point performance per watt of Fermi. With GF100 NVIDIA basically hit the wall for power consumption (and this is part of the reason current Tesla parts are running 448 out of 512 CUDA cores), so we’re basically looking at NVIDIA having to earn their performance improvements without increasing power consumption. They’re also going to have to earn their keep in sales, as NVIDIA is already talking about Kepler taking 2 billion dollars to develop and it’s not out for another year.
The second GPU is Maxwell (named after James Clerk Maxwell, the physicist/mathematician), and will be released some time in 2013. Compared to Fermi it should offer 10-12 times the DP FP performance per watt, which means it’s roughly another 3x increase over Kepler.
![]()
NVIDIA GPUs and manufacturing processes up to Fermi
NVIDIA still has to release the finer details of the GPUs, but we do know that Kepler and Maxwell are tied to the 28nm and 22nm processes respectively. So if nothing else, this gives us strong guidance on when they would be coming out, as production-quality 28nm fabrication suitable for GPUs is still a year out and 22nm is probably a late 2013 release at this rate. What’s clear is that NVIDIA is not going to take a tick-tock approach as stringently as Intel did – Kepler and Maxwell are going to launch against new processes – but this is only about GPUs for NVIDIA’s compute efforts. It’s likely the company will still emulate tick-tock to some degree, producing old architectures on new processes first; similar to how NVIDIA’s first 40nm products were the GT21x GPUs. In this scenario we’re talking about low-end GPUs destined for life in consumer video cards, so the desktop/graphics side of NVIDIA isn’t bound to this schedule like the Fermi/compute side is.
At this point the biggest question is going to be what the architecture is. NVIDIA has invested heavily in their current architecture ever since the G80 days, and even Fermi built upon that. It’s a safe bet that these next two GPUs are going to maintain the same (super)scalar design for the CUDA cores, but beyond that anything is possible. This also doesn’t say anything about what the GPUs’ performance is going to be like under single precision floating point or gaming. If NVIDIA focuses almost exclusively on DP, we could see GPUs that are significantly faster at that while not being much better at anything else. Conversely they could build more of everything and these GPUs would be 3-4 times faster at more than just DP.
Gaming of course is a whole other can of worms. NVIDIA certainly hasn’t forgotten about gaming, but GTC is not the place for it. Whatever the gaming capabilities of these GPUs are, we won’t know for quite a while. After all, NVIDIA still hasn’t launched GF108 for the low-end.
Wrapping things up, don’t be surprised if Kepler details continue to trickle out over the next year. NVIDIA took some criticism for introducing Fermi months before it shipped, but it seems to have worked out well for the company anyhow. So a repeat performance wouldn’t be all that uncharacteristic for them.
And on that note, we’re out of here. We’ll have more tomorrow from the GTC show floor.








82 Comments
View All Comments
iwodo - Wednesday, September 22, 2010 - link
No mention of CUDA -X86?? i thought it is the most significant announcementMjello - Wednesday, September 22, 2010 - link
If they manage to make their gpu's do x86-64 flawlessly (well as flawlessly as anyone can, but at least on par with intel/amd) without a dedicated x86 core to do the logic I'll be gawking foolishly... Anyway its gonna be at least a year or two.GrowMyHair - Wednesday, September 22, 2010 - link
I think it is the other way around: make x86 cores do cuda calculations. So that everyone will easily adopt cuda and turns to NVIDIA afterwards for a significant performance increase of their new cuda programs.mcnabney - Wednesday, September 22, 2010 - link
Nvidia doesn't have a license to produce hardware based on the x86 architecture. They can emulate it, but can't produce the actual cores.Lanskuat - Wednesday, September 22, 2010 - link
x86 CUDA only for programmers to debug code and for some cases then complied application was run on non CUDA system, so now such applications need to have other branch of code in native x86, but with x86 CUDA they will work slower thinking, that still running on CUDA NVidia card.iwodo - Wednesday, September 22, 2010 - link
No no no - CUDA for X86, basically you can run CUDA programs on x86, it was announced in GTC and widely reported in other sits. Just wondering why anand did not menton it.aegisofrime - Wednesday, September 22, 2010 - link
Doesn't that defeat the purpose of nVidia's GPU computing efforts ? Afterall nVidia has been touting GPU computing as offering a lot more performance than conventional x86 CPUs. It will be hilarious if we see one piece of CUDA code run faster on Sandy Bridge or Bulldozer than on Kepler :DFITCamaro - Wednesday, September 22, 2010 - link
As another said, if they make it available for x86, more programs will be written that use it. Then it is easier for people to transition over to Nvidia GPUs for a large speed increase.Cerb - Wednesday, September 22, 2010 - link
It won't. The kinds of things it is good for are generally tens to thousands of times faster on the GPU. If new CPUs double the cores, and increase IPC by 20% v. last gen, that's not even a 3x speedup. Even if the CPU could compete in raw performance, the GPU would have it in performance/watt by miles--which is part of why that is what they stress on their graph. CPUs are scaling up better w/o hitting power walls, but when those walls get reached, the CPU is at a disadvantage.Natfly - Wednesday, September 22, 2010 - link
Most significant as in their latest attempt at vendor lock-in. It'd be nice if they un-crippled their cpu physx libraries.