CEVA Announces NeuPro-S Second-Generation NN IP
by Andrei Frumusanu on September 17, 2019 7:00 AM EST- Posted in
- SoCs
- Machine Learning
- Neural Networks
- CEVA
- NeuPro
- NeuPro-S
It’s been a few years since machine learning and neural networks first started to be the hot new news topic. Ever since then, the market has transformed a lot and a lot of companies and the industry as a whole has shifted from a notion of “what can we do with this” to rather a narrative of “this is useful, we should really have it”. Although the market is very much far from being mature, it’s no longer in the early wild-west stages that we saw a few years ago.
A notable development in the industry is that there’s been a whole lot of silicon vendors who have chosen to develop their own IP instead of licensing things out – in a sense IP vendors were a bit behind the curve in terms of actually offering solutions, forcing in-house developments in order for their product not to fall behind in competitiveness.
Today, CEVA announces the new second generation of NeuPro neural networks accelerators, the new NeuPro-S. The new offering improves and advances the capabilities seen in the first generation, with CEVA also improving vendor flexibility and a new product offering that embraces the fact that a wide range of vendors now have their own in-house IP.
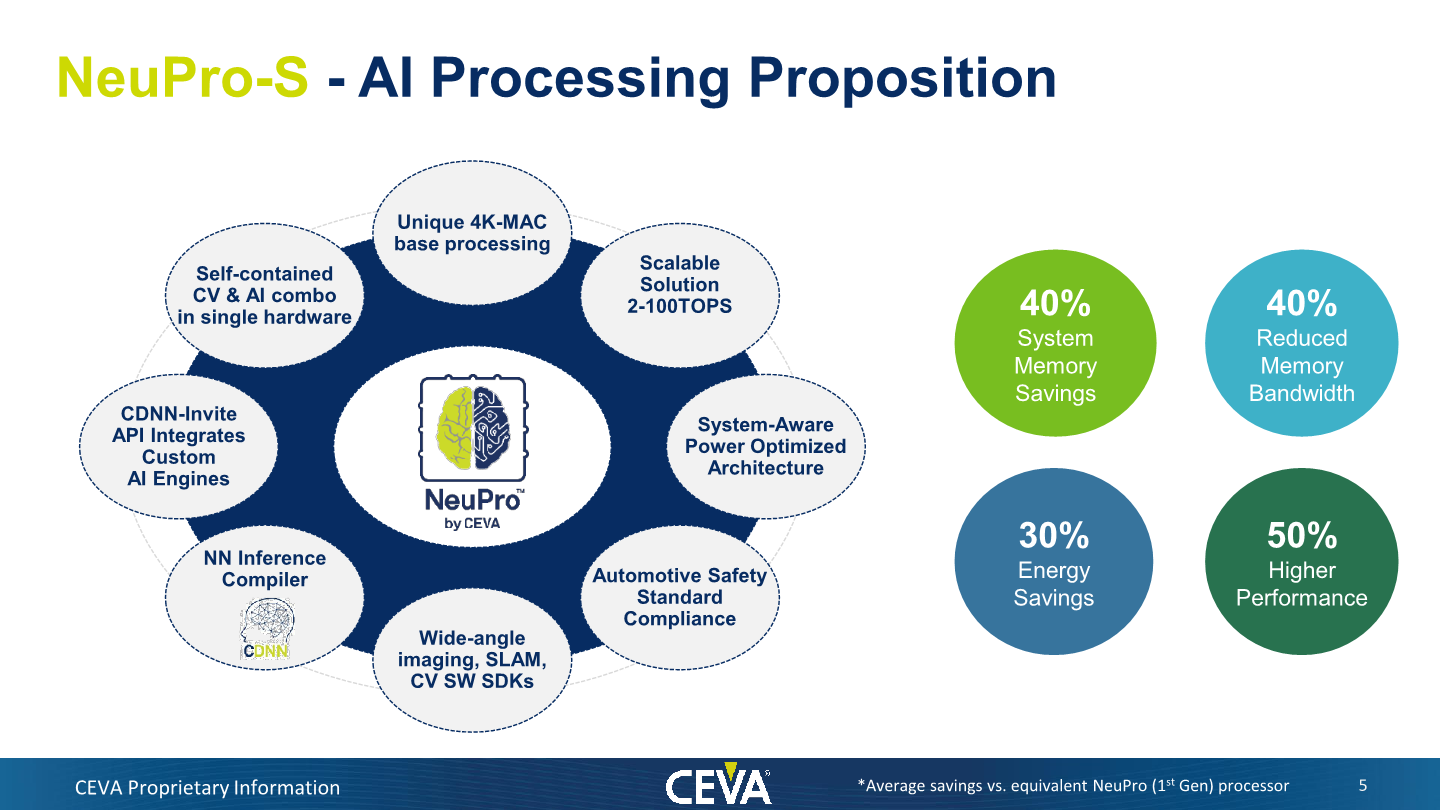
The NeuPro-S is a direct successor to last year’s first-generation NeuPro IP, improving on the architecture and microarchitecture. The core improvements of the new generation lie around the way the block now improves and handles memory, including new compression and decompression of data. CEVA quotes figures such as 40% reduces memory footprint and bandwidth savings, all while enabling energy efficiency savings of up to 30. Naturally this also enables for an increase in performance, claiming up to 50% higher peak performance in a similar hardware configuration versus the first generation.

Diving deeper into the microarchitectural changes, innovations of the new generation includes new weight compression as well as network sparsity optimisations. The weight data is retrained and compressed via CDNN via CEVA’s offline compiler and remains in a compressed form in the machine’s main memory – with the NeuPro-S decompressing in real time via hardware.
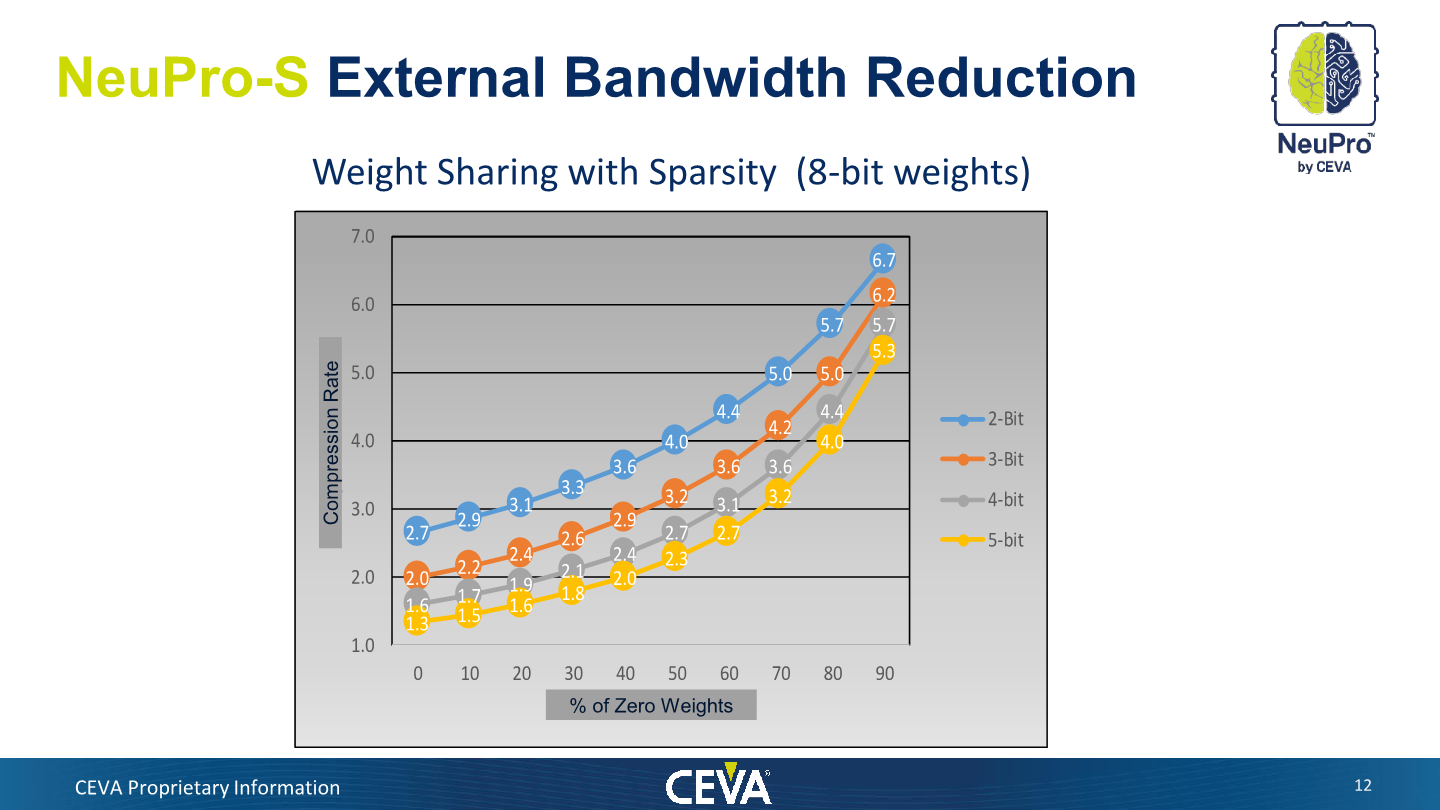
In essence, the new compression and sparsity optimisation sound similar to what Arm is doing in their ML Processor with zero-weight pruning in the models. CEVA further goes on to showcase the compression rate factors that can be achieved – with the factor depending on the % of zero-weights as well as the weight sharing bit-depth. Weight-sharing is a further optimisation of the offline compression of the model which reduces the actual footprint of the weight data by sharing finding commonalities and sharing them across each other. The compression factors here range from 1.3-2.7x in the worst cases with few sparsity improvements to up to 5.3-.7x in models with significant amount of zero weights.
Further optimisations on the memory subsystem level includes a doubling of the internal interfaces from 128-bit AXI to 256-bit interfaces, enabling for more raw bandwidth between the system, CEVA XM processor and the NeuPro-S processing engine. We’ve also seen an improvement of the internal caches, and CEVA describe the L2 memory utilisation to have been optimised by better software handling.
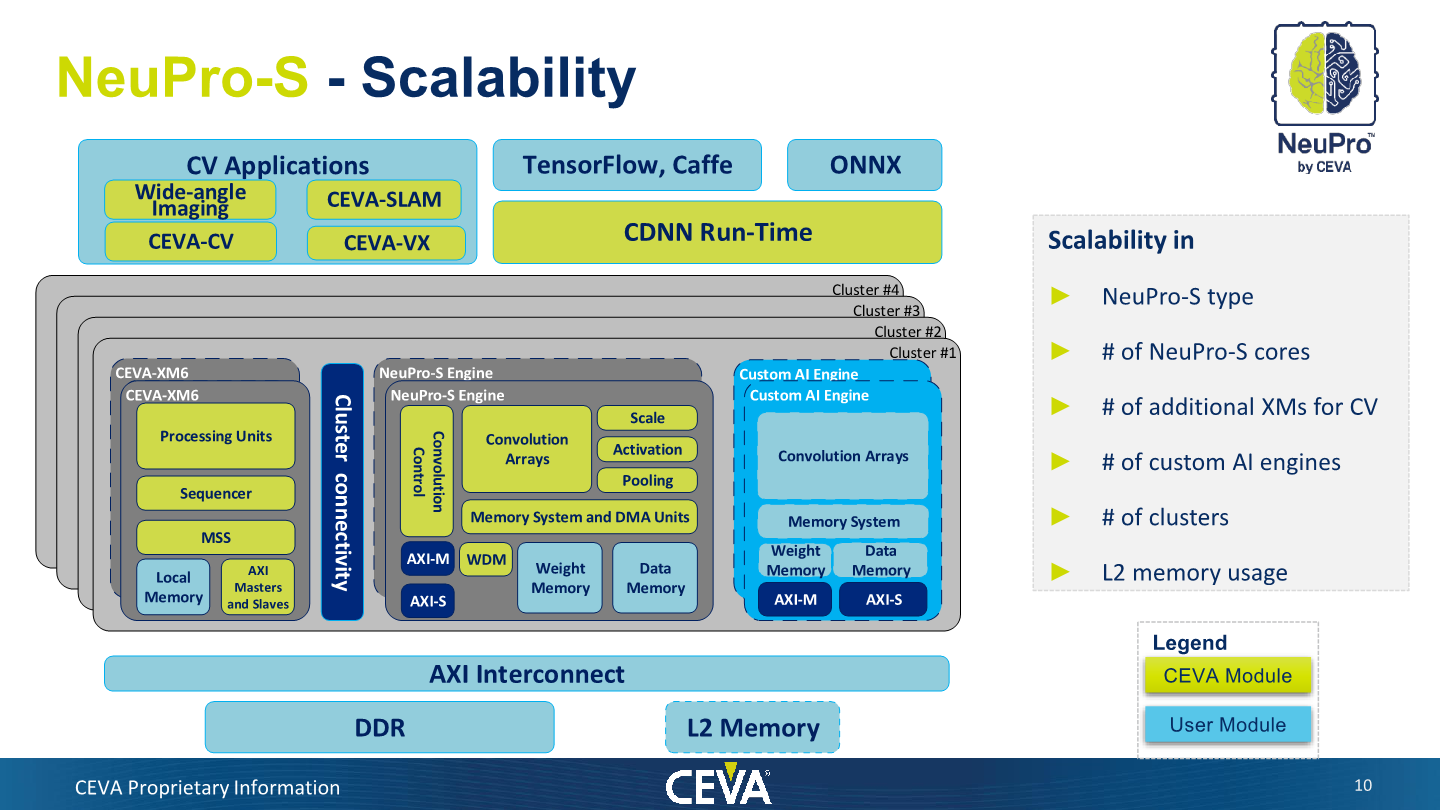
In terms of overall scaling of the architecture, the NeuPro-S doesn’t fundamentally change compared to its predecessor. CEVA doesn’t have any fundamental limit here in terms of the implementation of the product and they will build the RTL based on a customer’s needs. What is important here is that there’s a notion of clusters and processing units within the clusters. Clusters are independent of each other and cannot work on the same software task – customers would implement more clusters only if they have a lot of parallel workloads on their target system – for example this would make sense in an automotive implementation with many camera streams, but wouldn’t necessarily see a benefit in a mobile system. The cluster definition is a bit odd and wasn’t quite as clear whether it’s actually any kind of hardware delimitation, or the more likely definition of software operation of different coherent interconnect blocks (As it’s all still connected via AXI).
Within a cluster, the mandatory block is CEVA’s XM6 vision and general-purpose vector processor. This serves as the control processor of the system and takes care of tasks such as control flow and processing of fully-connected layers. CEVA notes that processing of ML models can be processed fully independently by the NeuPro-S system, whereas maybe other IPs need to still rely on maybe the CPU for some processing of some layers.
The NeuPro-S engines are naturally the MAC processing engines that add the raw horsepower for wider parallel processing and getting to the high TOPS figures. A vendor needs at minimum a ratio of 1:1 XM to NeuPro engines, however it may chose to employ more XM processors which may be doing separate computer visions tasks.
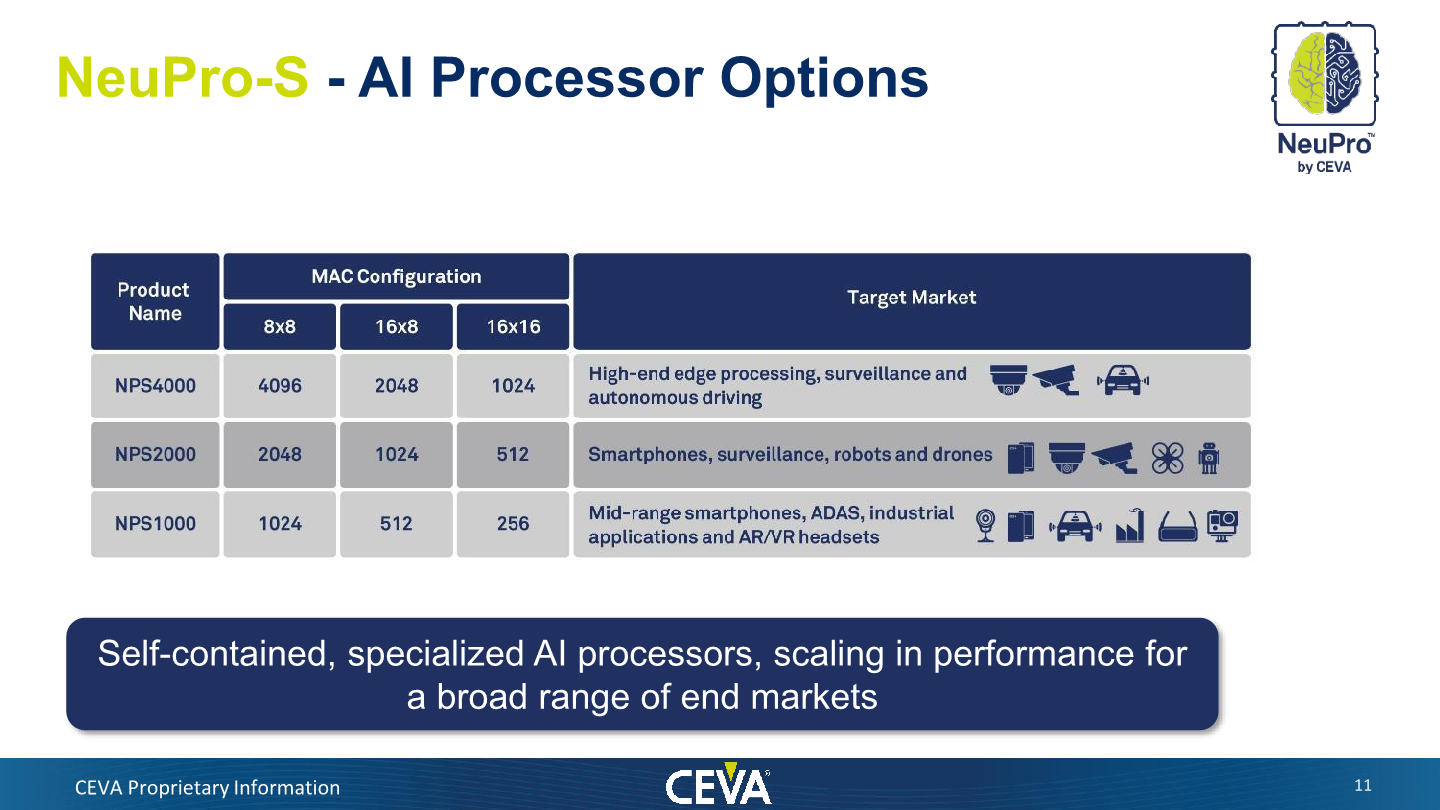
CEVA allows allow scaling of the MAC engine size inside a single NeuPro-S block, which ranges from 1024 8x8 MACs to up to 4096 MACs. The company also allows for different processing bit-depths, for example allowing 16x16 as it still sees the need for some use cases that take advantage of the higher precision 16-bit formats. There are also mixed format configurations like 16x8 or 8x16 where the data and weight precision can vary.
In total, a single NeuPro-S engine in its maximum configuration (NPS4000, 4096 MACs) is quoted as reaching up to 12.5 TOPS on a reference clock of 1.5GHz. Naturally the frequency will vary based on the implementation and process node that the customer will deploy.

As some will have noted in the block diagram earlier, CEVA also now allows the integration of third-party AI engines into their CDNN software stack and to interoperate with them. CEVA calls this “CDNN-Invite”, and essentially the company here is acknowledging the existence of a wide-range of custom AI accelerators that have been developed by various silicon vendors.
CEVA wants to make available their existing and comprehensive compiler and software to vendors and enable them to plug-in their own NN accelerators. Many vendors who chose to go their own route likely don’t have quite as extensive software experience or don’t have quite as much resources developing software, and CEVA wants to enable such clients with the new offering.
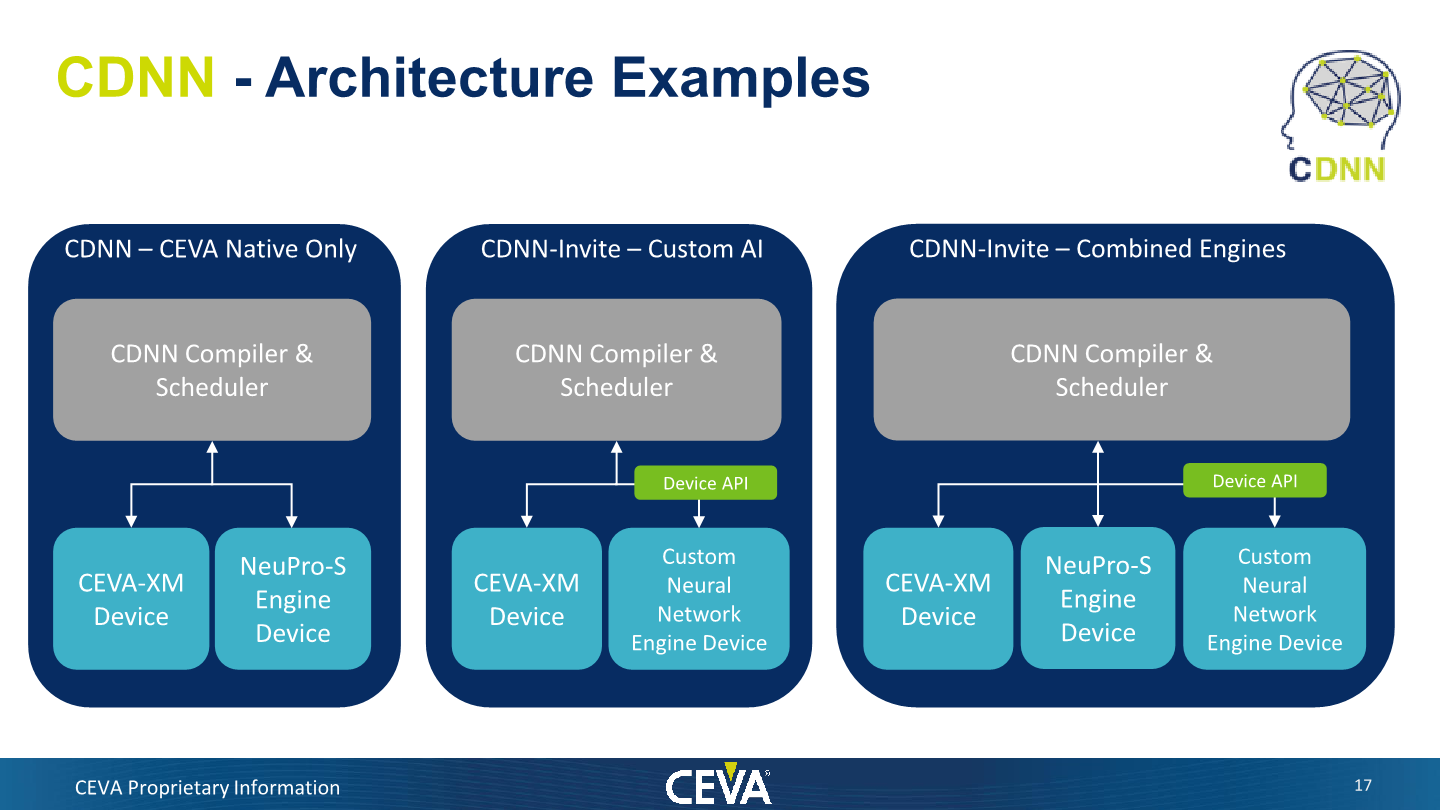
While the NeuPro-S would remain a fantastic choice for generic NN capabilitites, CEVA admits that there might be custom accelerators out there which are hyper-optimised for certain specific tasks, reaching either higher performance or efficiency. Vendor could thus have the best of both worlds by having a high degree of flexibility, both in software and hardware. One could choose to use the NeuPro-S as the accelerator engine, use just their own IP, or create a system with both units. The only requirement here is that a XM processor be implemented as a minimum.
CEVA claims the NeuPro-S is available today and has been licensed to lead customers in automotive camera applications. As always, silicon products are likely 2 years away.





Related Reading:
- CEVA Announces NeuPro Neural Network IP
- CEVA Launches Fifth-Generation Machine Learning Image and Vision DSP Solution: CEVA-XM6
- Cadence Announces The Tensilica DNA 100 IP: Bigger Artificial Intelligence
- ARM Details "Project Trillium" Machine Learning Processor Architecture
- ARM Announces Project Trillium Machine Learning IPs
- Imagination Announces First PowerVR Series2NX Neural Network Accelerator Cores: AX2185 and AX2145








5 Comments
View All Comments
abufrejoval - Tuesday, September 17, 2019 - link
Interesting and nice writeup!I have absolutely no problem imagining a need for several clusters on mobiles even today:
You could be running ground truth detection 3D mapping from the camera, but need another cluster for sensor fusion using gyros/gravity/magnetic sensors, you may want to mix in object/subject detection and inventory, you still may want to run speech models for recognition, synthesis, BERT or another complex LSTM etc.
And these could require rather distinct rate of compute vs. I/O while nothing and no-one could schedule them on an NN-core today like compute tasks on a CPU: It's a GPU-scheduling-nightmare³...
You'd want plenty of clusters and the ability to partition the power for sustaining a couple of distinct workloads.
p1esk - Tuesday, September 17, 2019 - link
Products are 2 years away? So is this chip better than what Nvidia will release in 2 years?name99 - Tuesday, September 17, 2019 - link
As a comparison, the A13's NPU is at 6TOPs (so half their peak, and what they are targeting at high-end smartphone) but available today.Apple is probably the most interesting example today (outside cars...) of using this stuff for vision. Obviously there is the computation photography stuff, but it's still the case that very few people have seen or experimented with
This is an interesting example because it's actually rather glitchy (very beta software demo'd at WWDC this year) and the glitches kinda show the reality (once the demo is too slick, it's hard to see the magic going on behind it).
https://www.youtube.com/watch?v=g8cf2gMarqo
The significant points to note (and the things that are newest code, so go wrong the worst!) are the way the AR occludes people BEHIND the bowling ball, but not people IN FRONT OF the bowling ball...
Obviously this stuff on a phone or iPad is using a less than ideal form factor; it's definitely a hassle to keep holding your device at the correct angle. (Even so it IS useful, and I've used it, to measure distances, or to see how a piece of furniture would fit in a room, or whether it can pass through a door.)
But I think it's significant to compare the gap between how much time Apple gives AR at developer-targeted events (lots!) vs at public-facing events (basically nothing!). It seems to me so obvious that Apple's strategy is to get developers (including their own developers) familiar with AR, and testing the hardware and algorithms, while the real public debut and fanfair will occur with the release of the Apple Glasses.
Is there any use for this stuff before then? Well the next aTV will have an A12 (and so a 5TOPs NPU) in it. I have visions of a a gaming setup that allows one for place an iPhone (for casual use) or a dedicated camera (maybe via USB or ethernet) for hardcore use on top of the TV, and use this AR/pose recognition stuff for things like DDR, or Wii and XBox games, or shared space remote games.
We'll see. (Apple's game team seem to be trying harder than usual this year to really kickstart games. BUT that same team also seem to have astonishingly limited imagination when it comes to actually allowing the aTV to open up to alternative input methods, like cameras. So...)
p1esk - Tuesday, September 17, 2019 - link
A couple of things:1. Apple does not really compete with anyone in terms of NN accelerators. I mean it seems like they just do whatever they feel like every generation.
2. This CEVA chip is strictly for cars. So it's gonna compete with Nvidia (mostly). As such, it's gotta be at least 2x better than whatever Nvidia releases after Amper, so it's a pretty high bar. I'm not holding my breath. But, competition is always good.
p1esk - Tuesday, September 17, 2019 - link
Sorry didn’t mean to reply to your comment