Hot Chips 2018: Arm's Machine Learning Core Live Blog
by Ian Cutress on August 21, 2018 4:55 PM EST
04:57PM EDT - Arm officially announced Project Trillium earlier this year, as a way to bring machine learning to the Arm ecosystem. As part of the trade show today, we have a presentation where Arm is going to talk about its first machine learning core. The talk is set to start at 2pm PT / 9pm UTC.

05:01PM EDT - Combined effort of large team
05:01PM EDT - 150+ people
05:02PM EDT - Arm works with partners across many segments. Without fail, all those markets want machine learning acceleration
05:02PM EDT - Need to come up with a fundamental tech that can be used for many different segments
05:03PM EDT - ML processor focused for Neural Networks
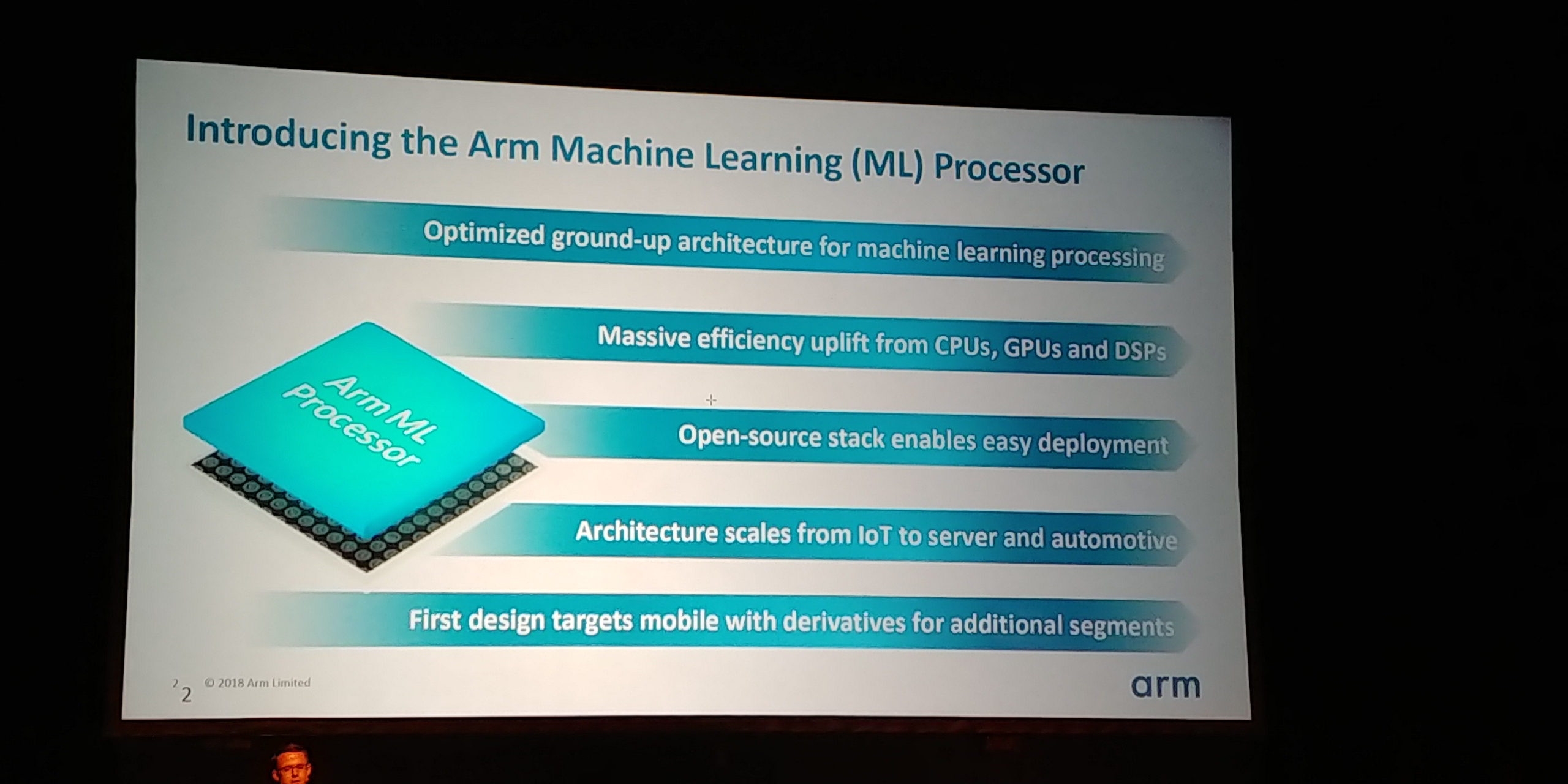
05:03PM EDT - Optimized ground up architecture
05:03PM EDT - open source stack for easy deployment
05:03PM EDT - First design targets mobile with derivatives for additional segments
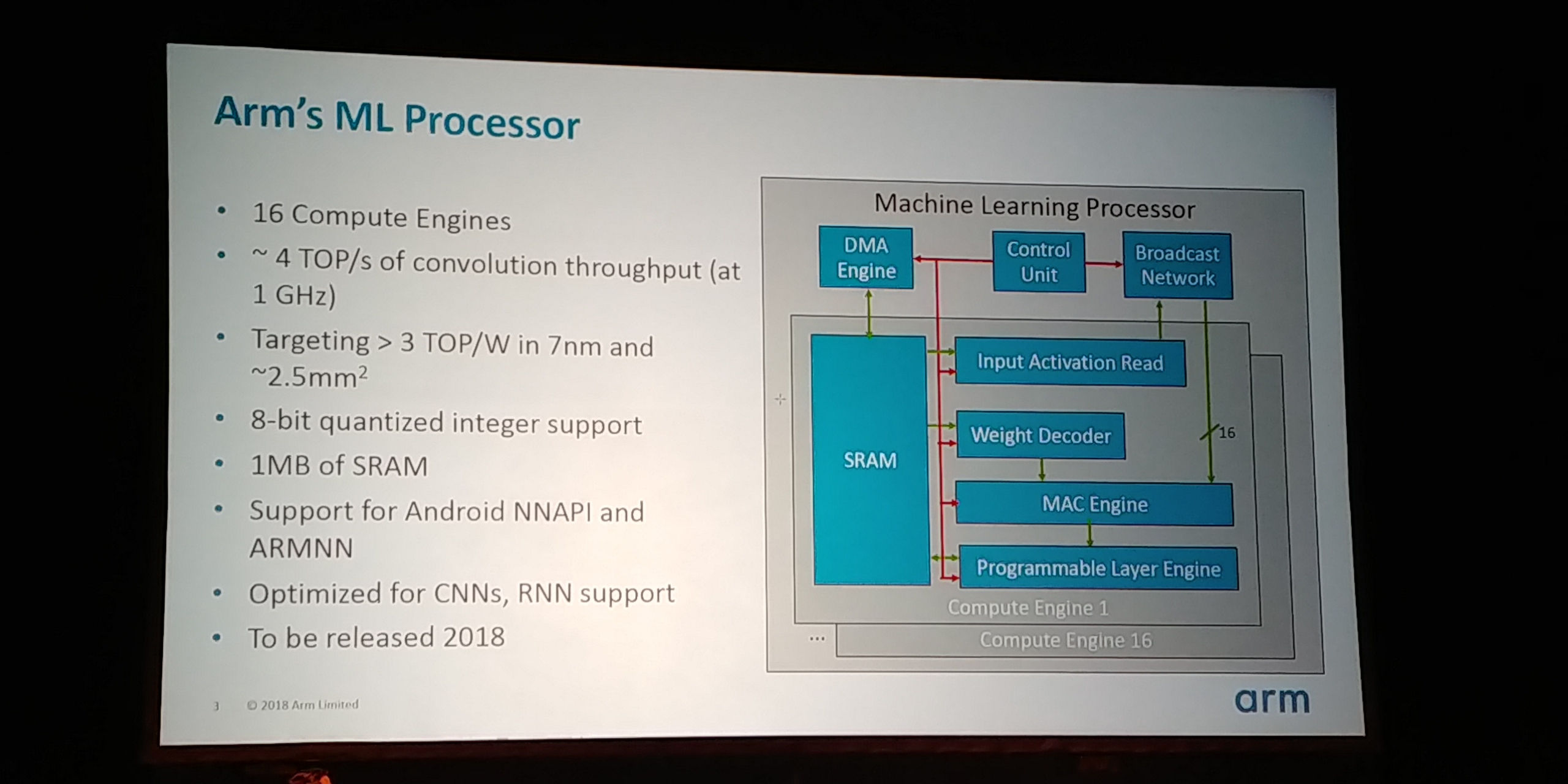
05:05PM EDT - Main component is the Machine Learning Processor. Biggest block is SRAM
05:05PM EDT - 16 compute engines per ML Proc
05:05PM EDT - 4 TOP/s of convolution at 1 GHz
05:05PM EDT - Targeting 3 TOP/W in 7nm and 2.5mm2
05:06PM EDT - INT8 support, support for NNAPI
05:06PM EDT - Optimized for CNN/RNN
05:06PM EDT - Support 16-bit, in case pixels are coming
05:06PM EDT - 8-bit is 4x perf over 16-bit
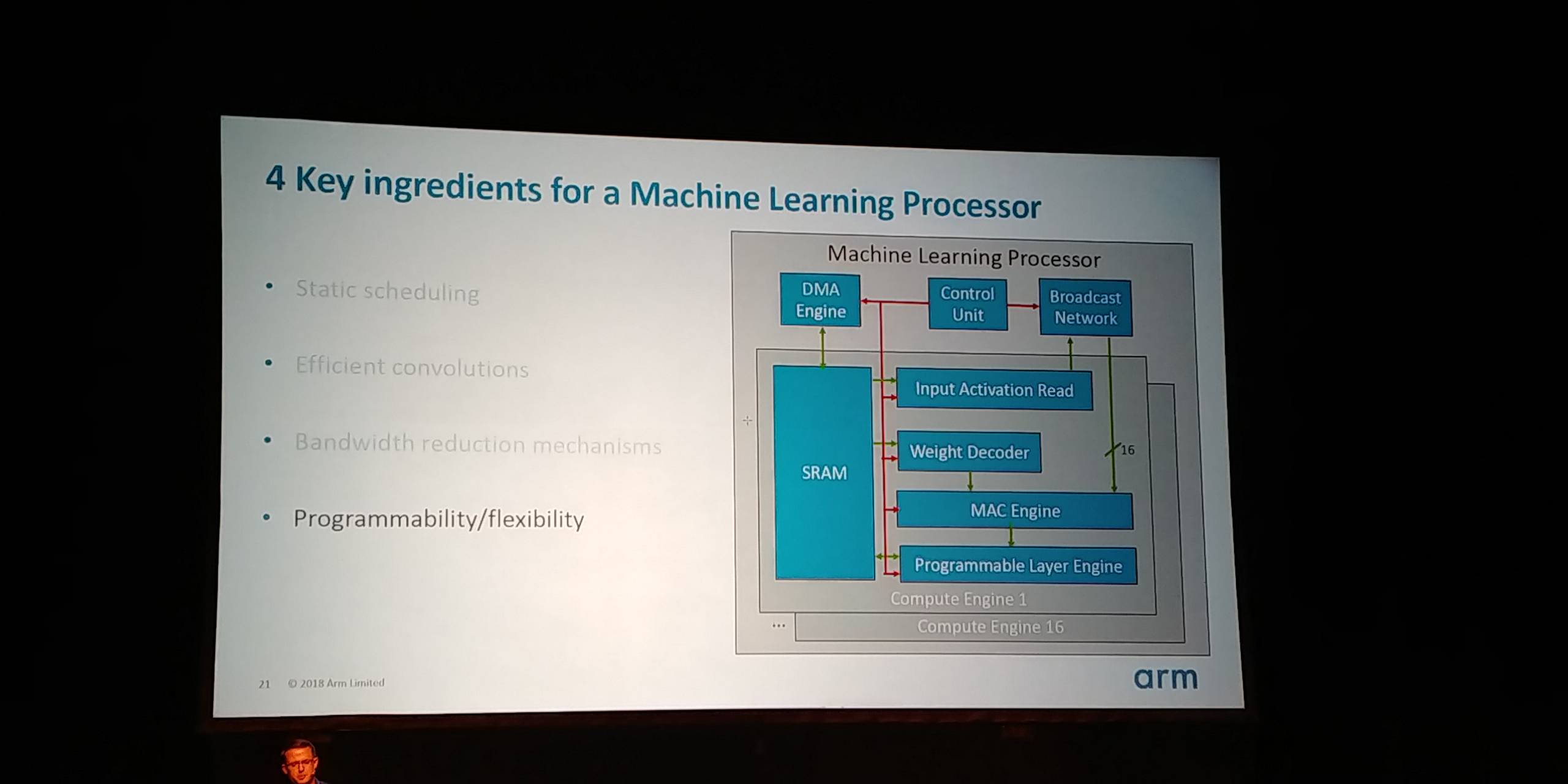
05:07PM EDT - Need to get four things right
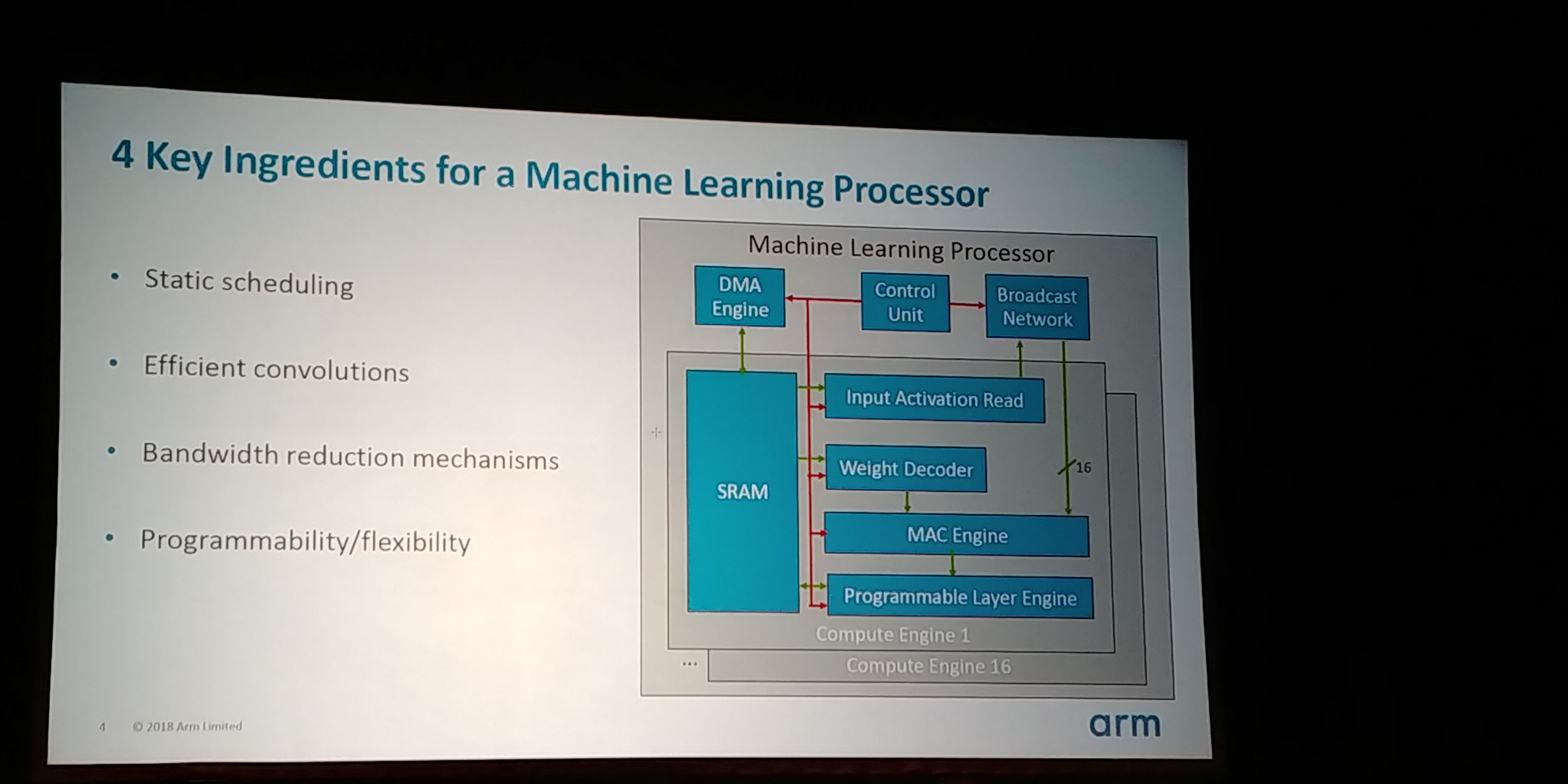
05:08PM EDT - Static Scheduling, Efficient Convolutions
05:08PM EDT - CNNs are static analyzable. So you can optimize for deterministic data with stuff laid out in memory ahead of time
05:08PM EDT - Creates command stream for different parts in the processor
05:09PM EDT - Control Unit takes command stream
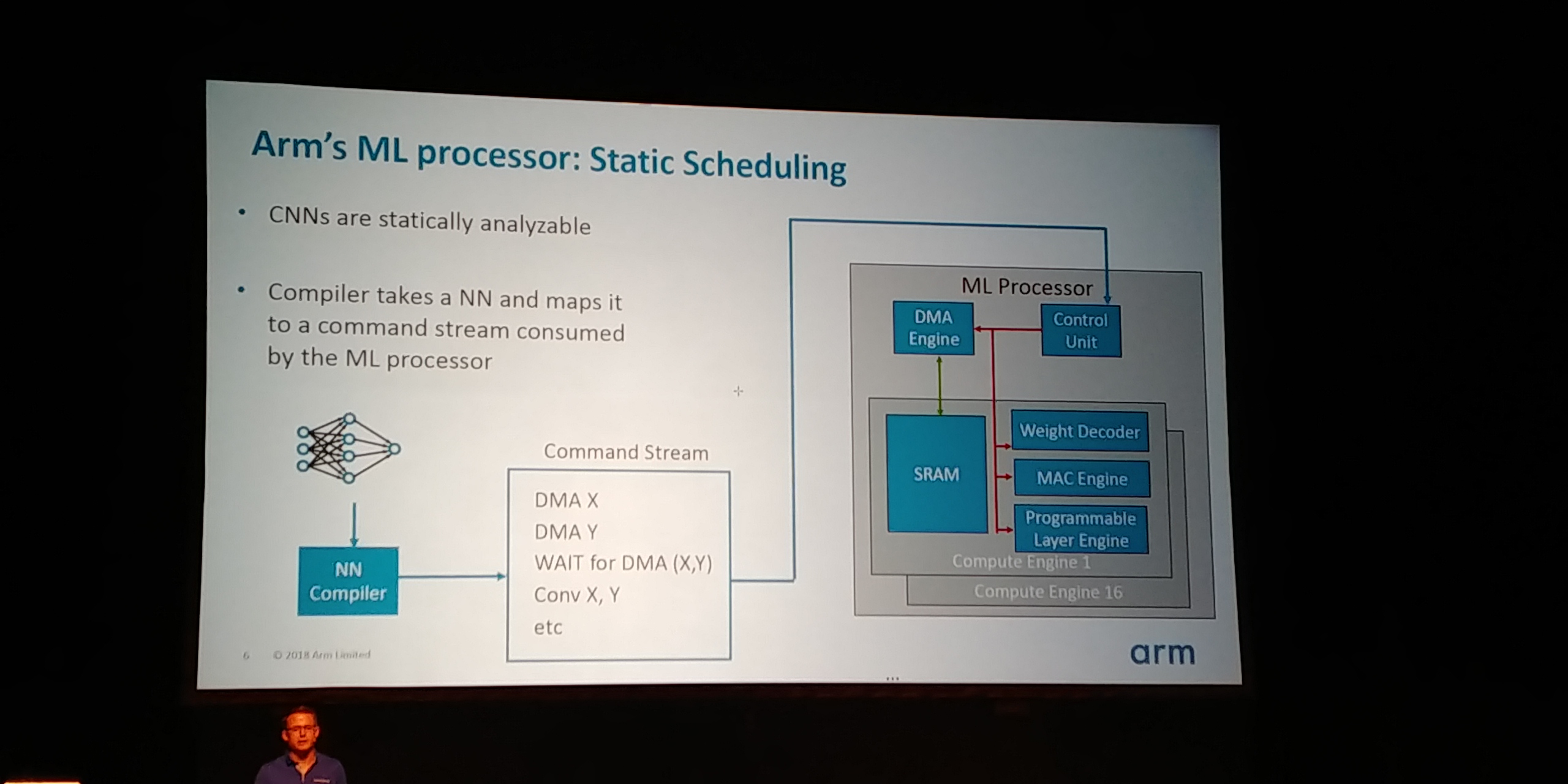
05:09PM EDT - No caches, simplified flow control. Simplified hardware (co-design with compiler). Predictable performance
05:10PM EDT - Compiler needs to know the details of the core, e.g. SRAM size
05:11PM EDT - Underlying requirement of high-throughput dot products are worth optimizing for
05:12PM EDT - Output feature maps are interleaved across compute engines
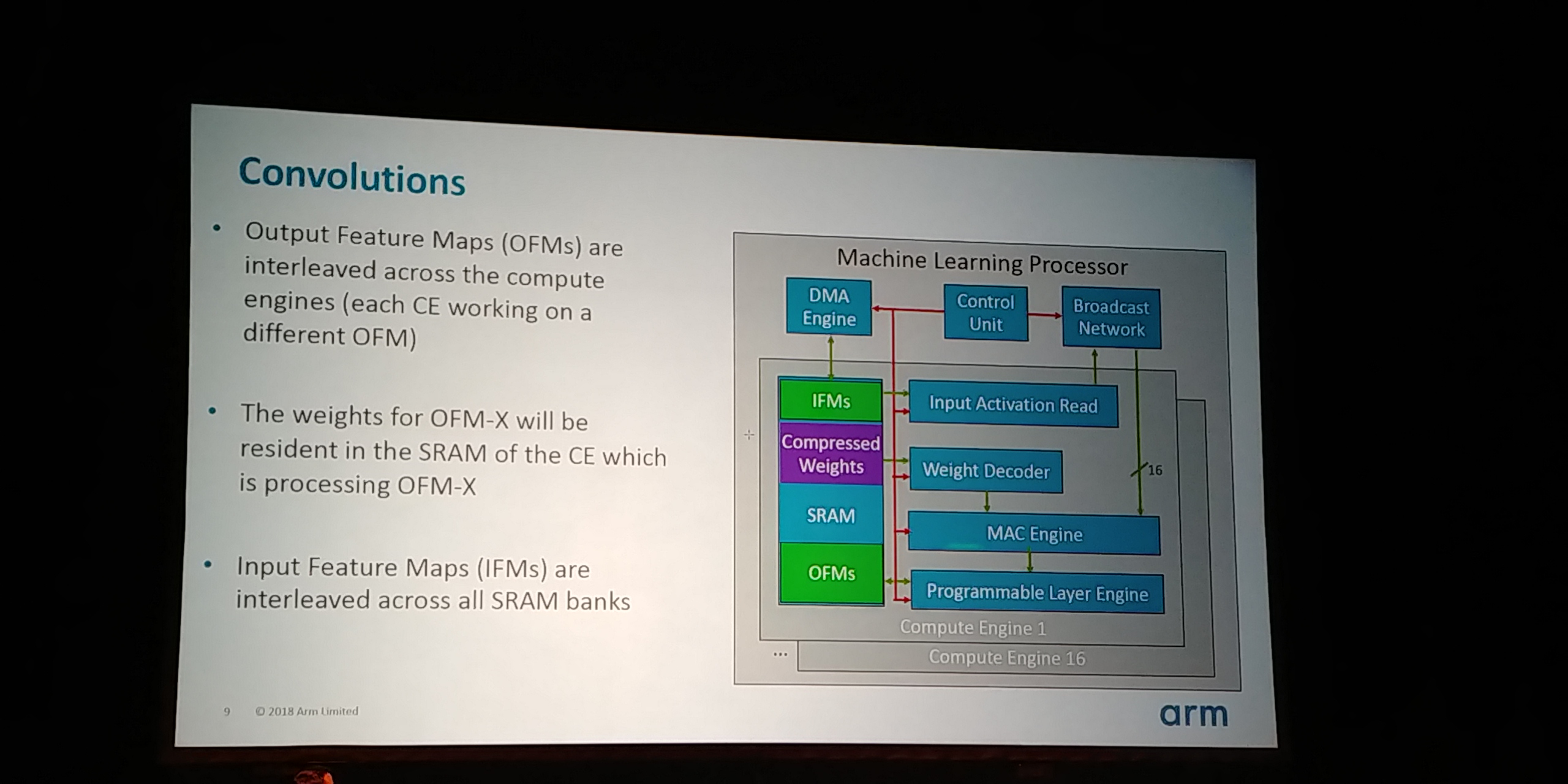
05:12PM EDT - So 16 engines = 16 output feature maps
05:12PM EDT - MAC Engine: 8 x 16-bit wide dot products per cycle
05:13PM EDT - Each engine is 2*8*16 = 256 ops/cycle
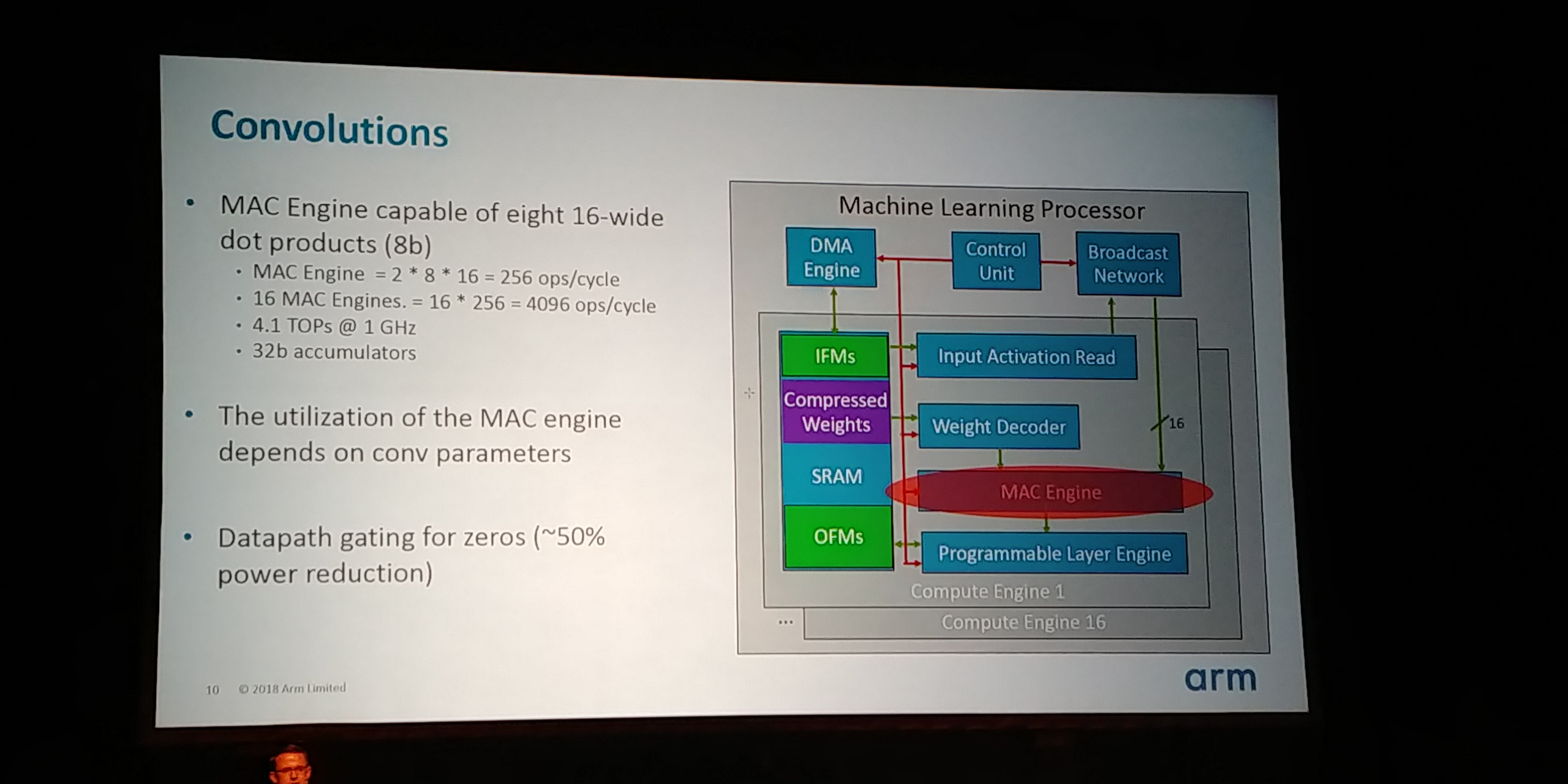
05:13PM EDT - 32b accumulators, 4.1 TOPs @ 1 GHz
05:13PM EDT - Gate for zeros to save power - 50% power reductions
05:13PM EDT - Keep inputs to datapaths stable to save energy
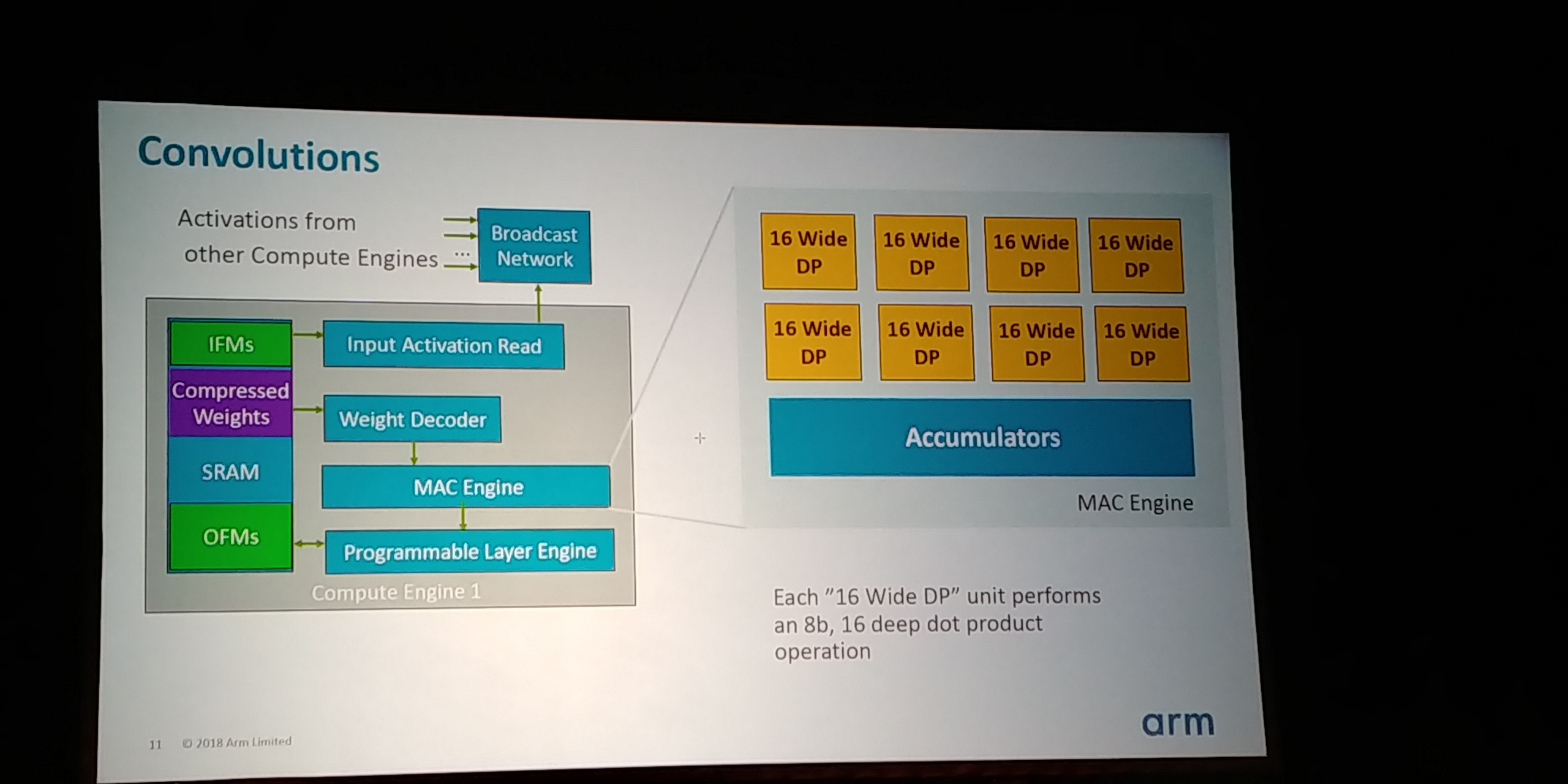
05:14PM EDT - Also have broadcast network

05:14PM EDT - Creates tensor block of activations that is broadcast to all the MAC engines
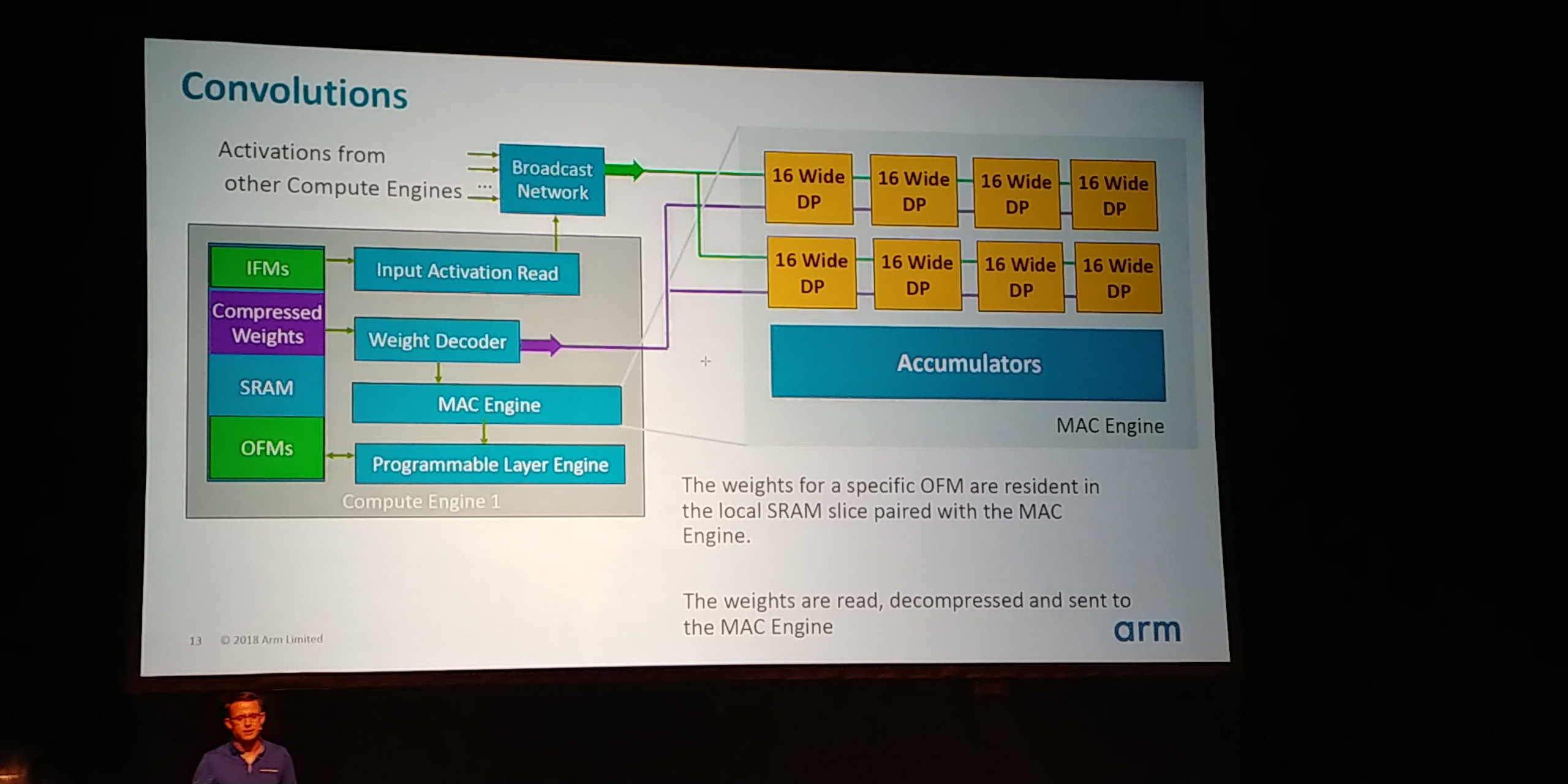
05:15PM EDT - when final result the 32b values are scaled back to 8b and sent to the programmable layer engine

05:15PM EDT - POP IP for Mac Engine for 16nm and 7nm
05:16PM EDT - Custom physical design with 40% area reduction and 10-20% power improvements
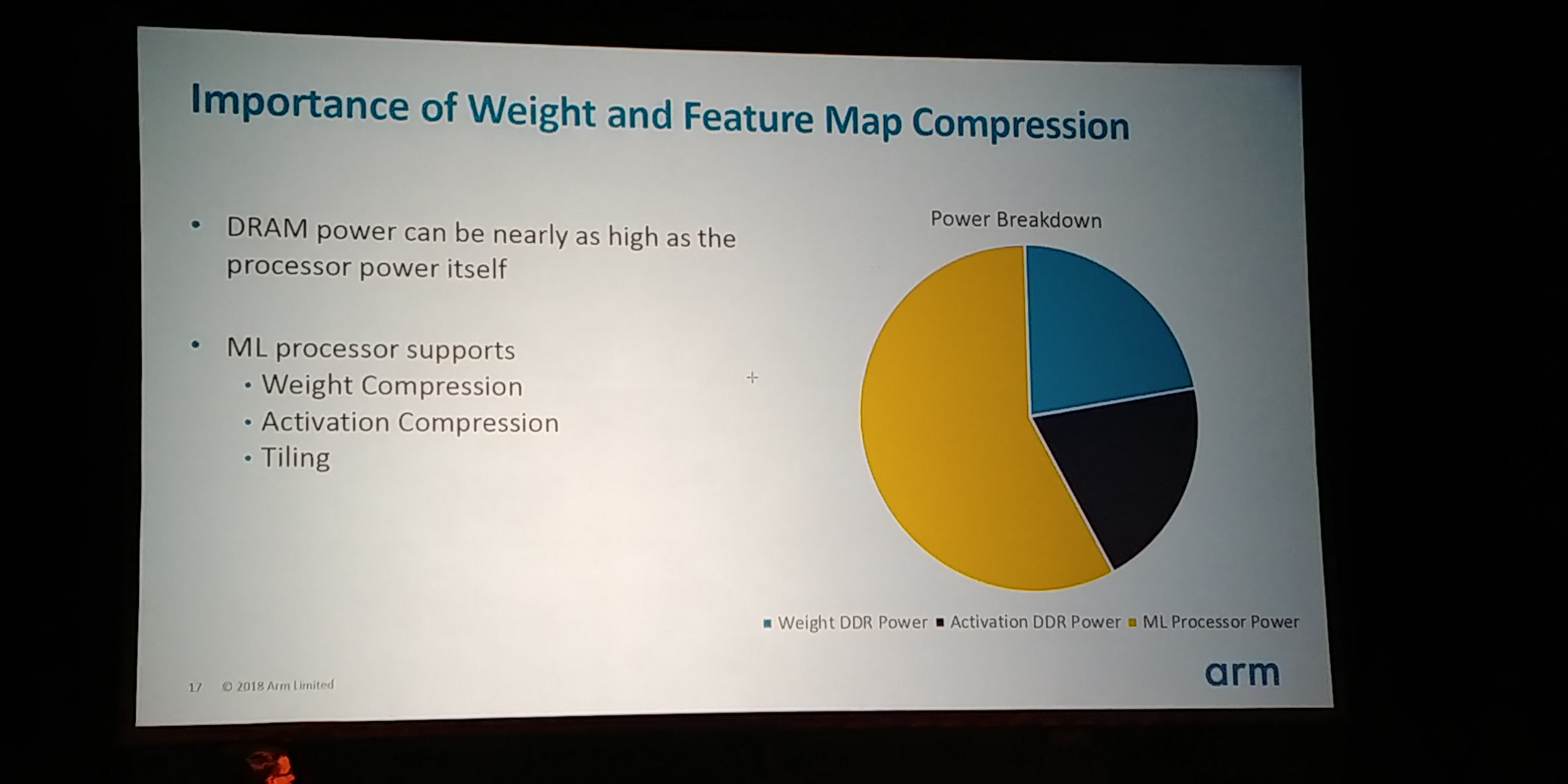
05:16PM EDT - DRAM power can be up to 50% without bandwidth saving
05:16PM EDT - use weight compression, activation compression, and tiling, to save DRAM power
05:17PM EDT - Spend dedicated silicon on compression is essential
05:18PM EDT - Histogram of 8x8 blocks in Inception V3 shows key ML matrixes
05:18PM EDT - Develop lossless compression for the popular 8x8 blocks
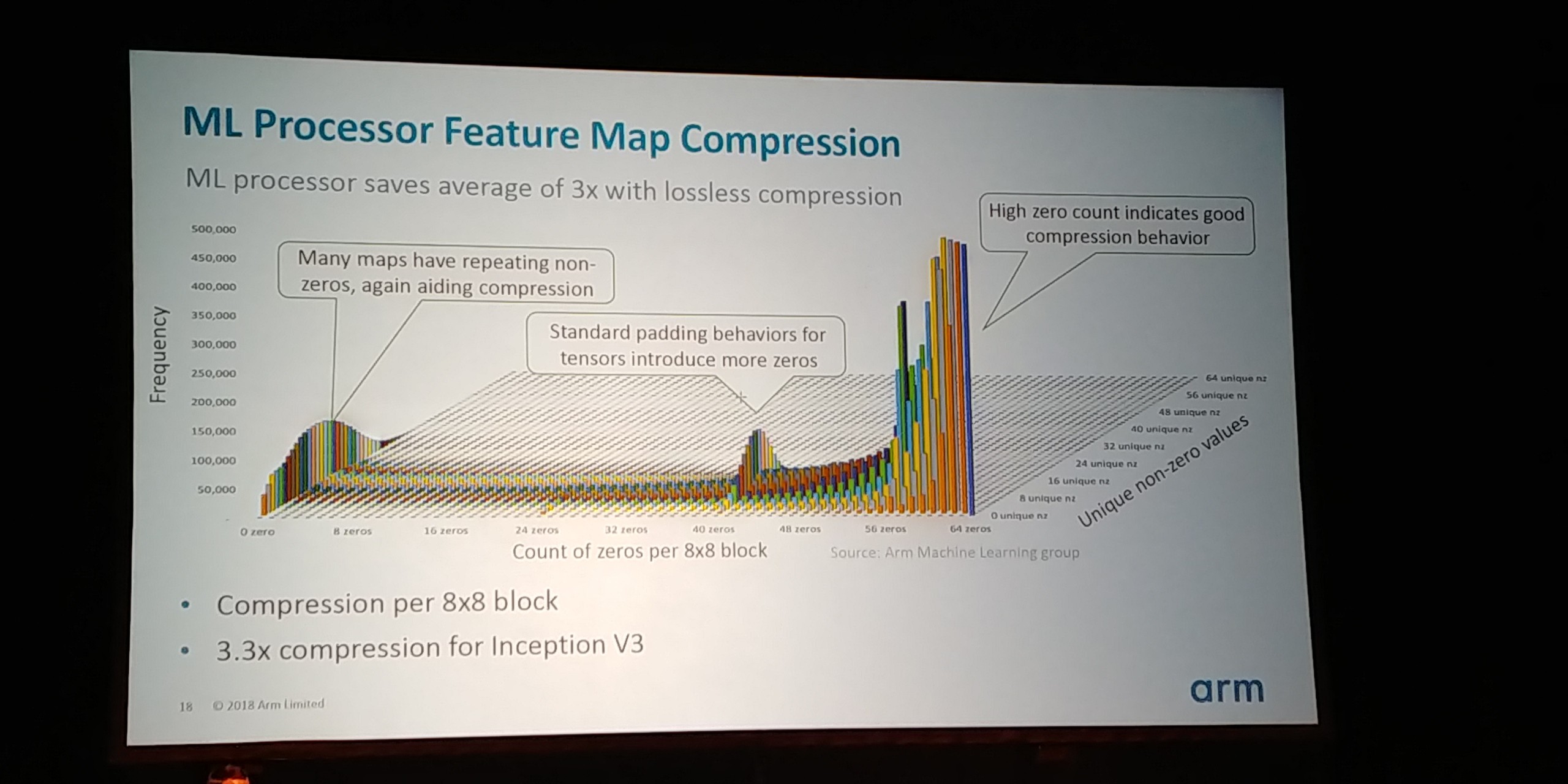
05:19PM EDT - 3.3x compression over standard implementation
05:19PM EDT - When training, many training weights taper down to zero
05:19PM EDT - Can force the weights to zero with no change in accuracy but offers better compression
05:20PM EDT - This allows for weight compression and 'pruning'
05:20PM EDT - Support a compression format to get the zeroes out
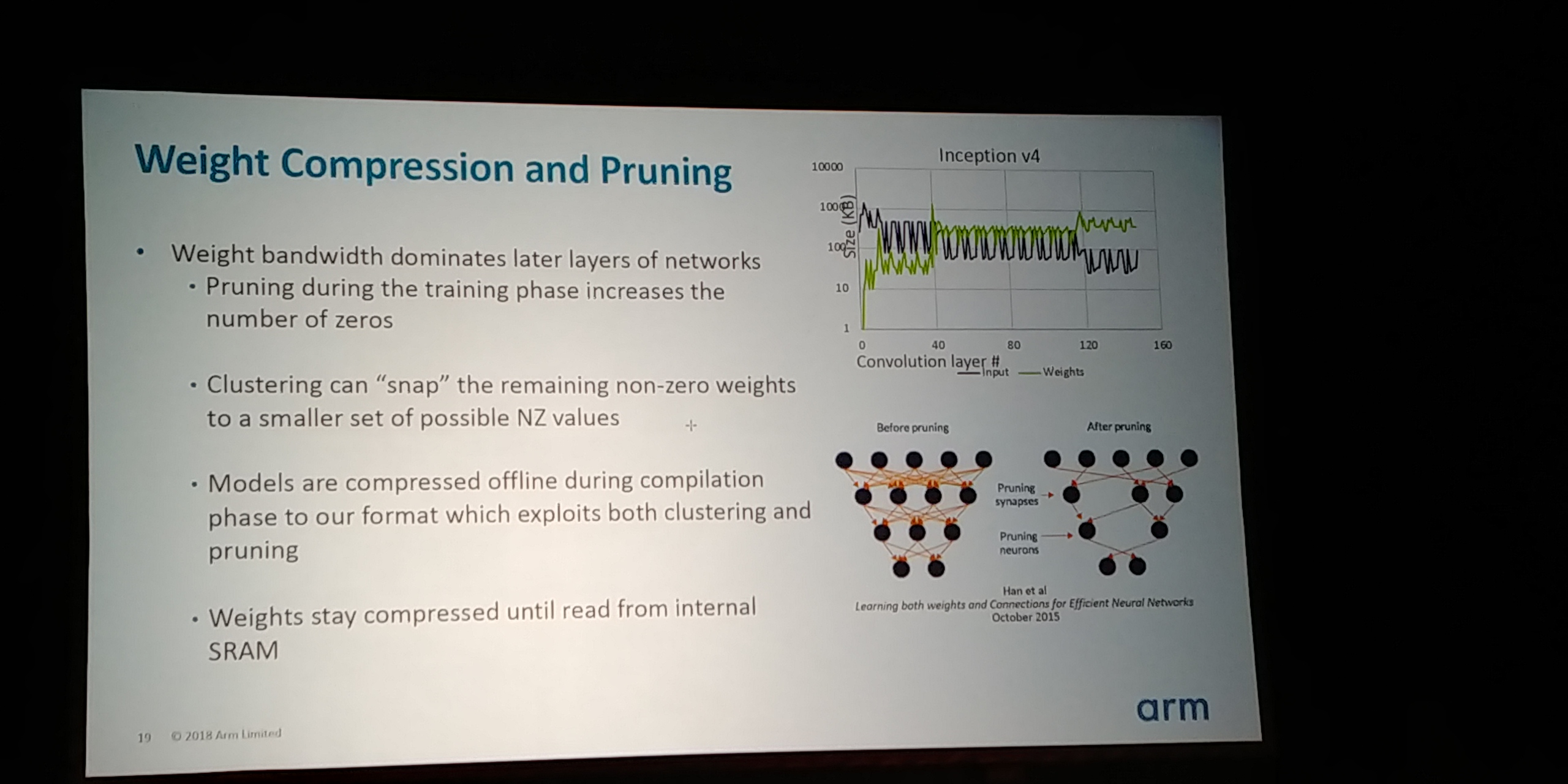
05:20PM EDT - Take the remaining non-zero can be clamped / normalized
05:20PM EDT - All happens in hardware
05:21PM EDT - Weights stay compressed until read from internal SRAM
05:21PM EDT - Very model dependent
05:21PM EDT - Tiling

05:22PM EDT - Tricks that the compiler can use to reduce bandwidth by using the SRAM
05:22PM EDT - Possible due to static scheduling
05:23PM EDT - State of the art in tiling is still evolving
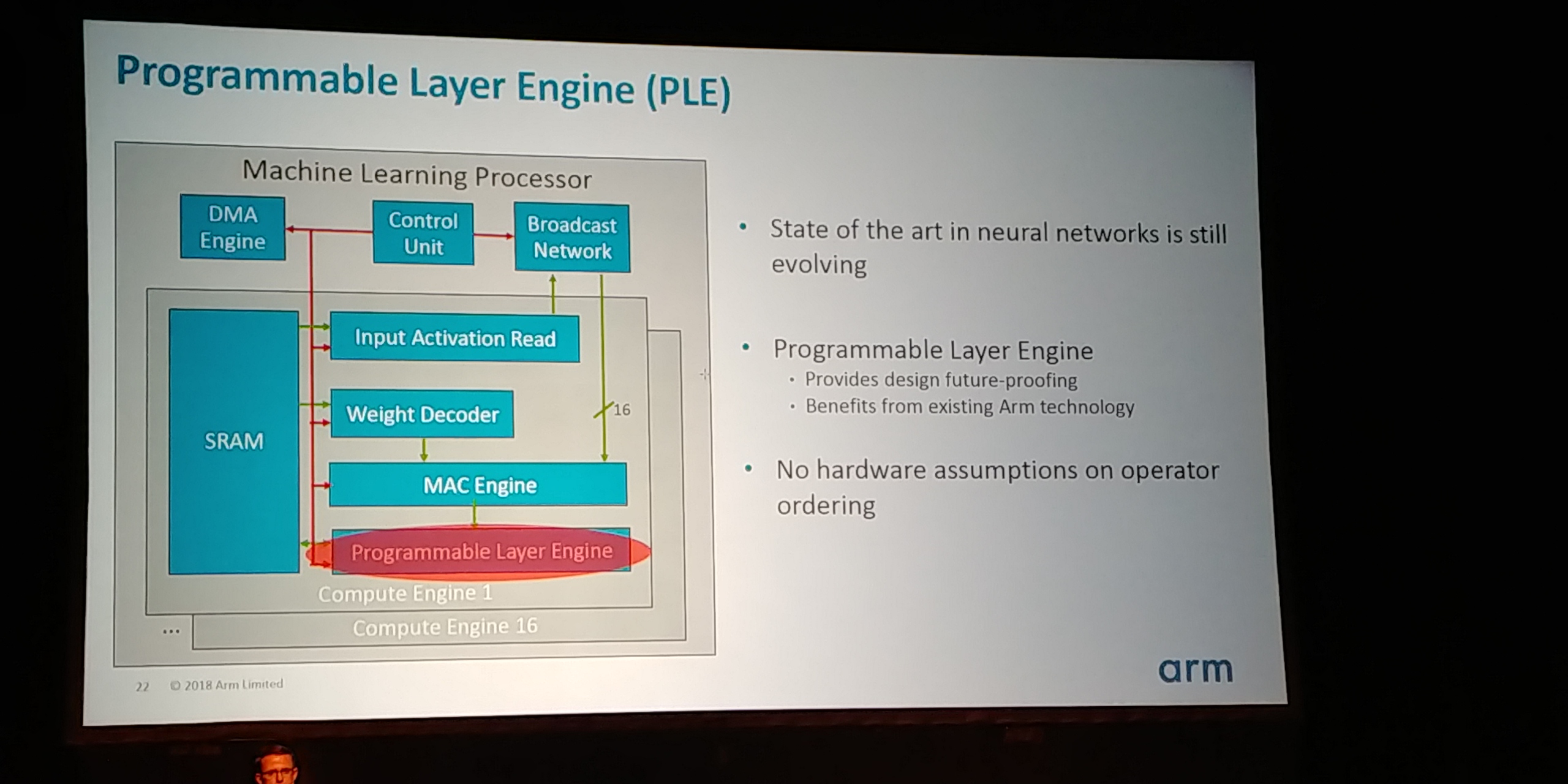
05:23PM EDT - Programmable Layer Engine helps with future-proofing
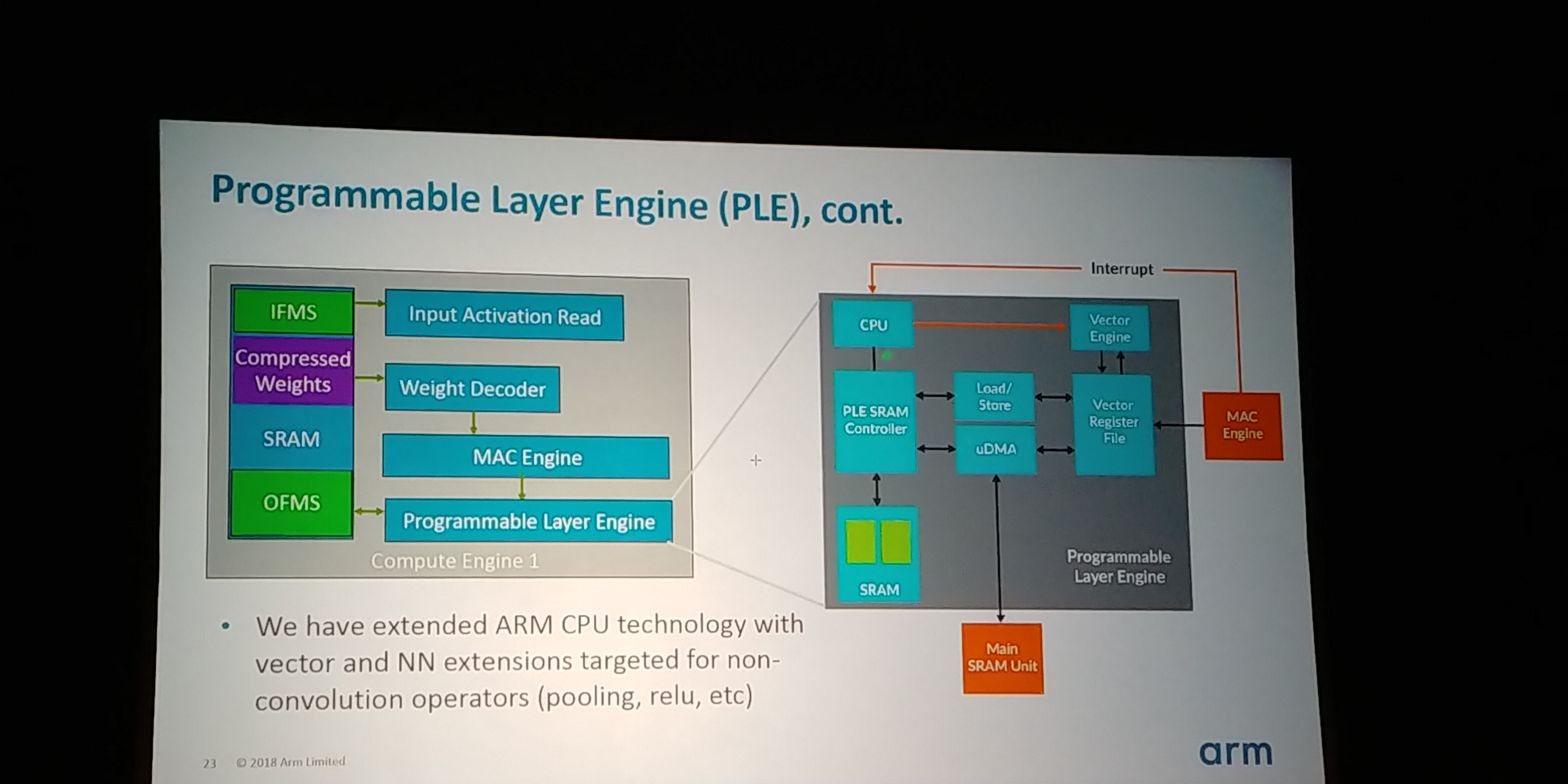
05:24PM EDT - Use Arm M-class CPU and extended it with vector extensions for neural networks

05:24PM EDT - Engine can manipulate SRAM data
05:25PM EDT - Designed to scale in engines
05:25PM EDT - Designed to scale with MAC engine throughput
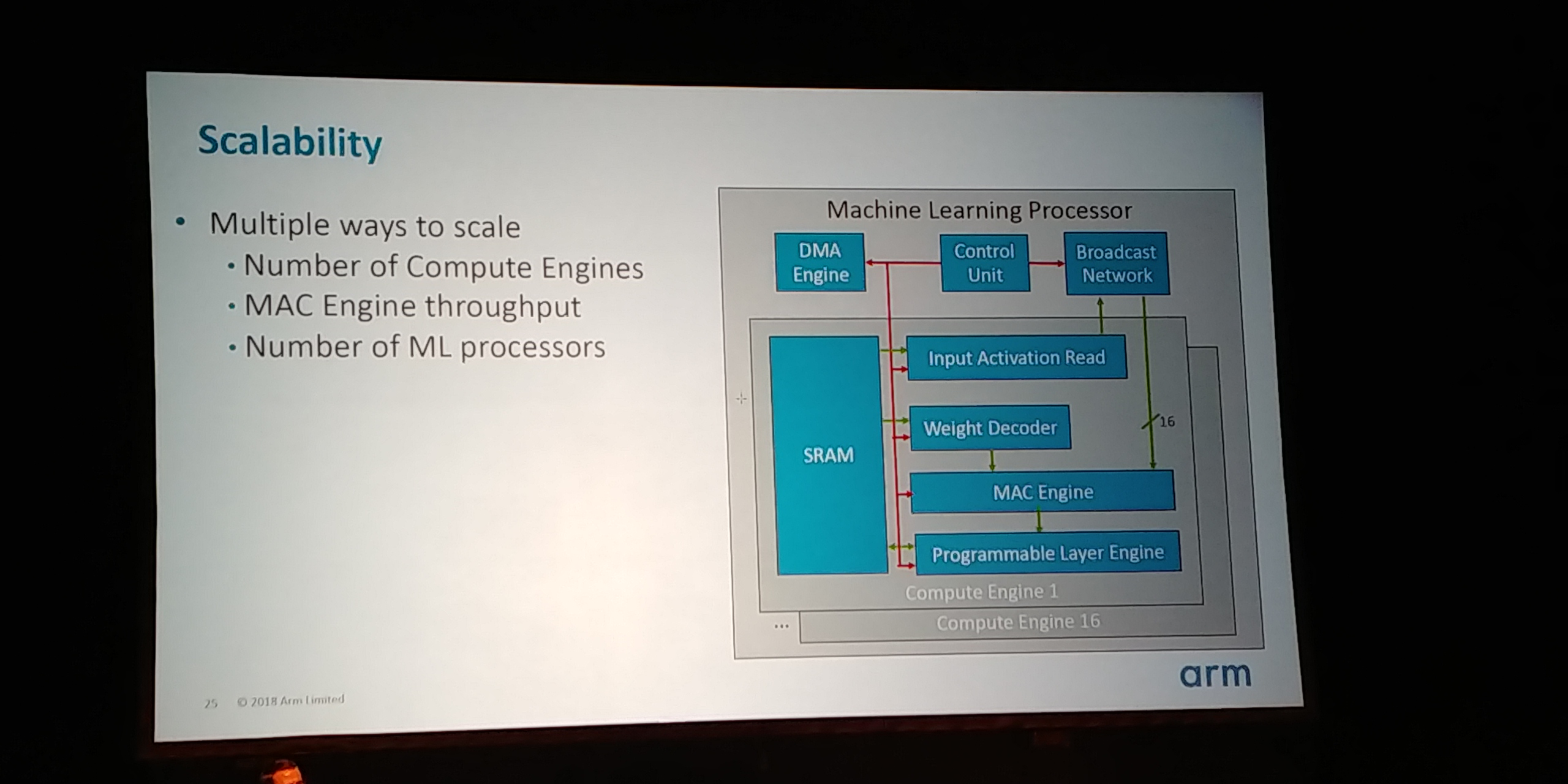
05:25PM EDT - Designed to scale with Machine Learning Processors for multiple workloads
05:26PM EDT - Q&A time
05:27PM EDT - Q: If there's one M-series core in the engine, is there 16 per MLP? A: Yes
05:28PM EDT - Q: What about lower than 8-bit? A: Industry momentum is around 8-bit. We're looking into lower bit levels, but that could be in the future
05:28PM EDT - Q: When will it be available for licencing ? A: Later this year
05:29PM EDT - That's a wrap. Come back at 3pm for a talk on Tachyum








1 Comments
View All Comments
eastcoast_pete - Thursday, August 23, 2018 - link
Any facts or even rumors on actual hardware partners (with fabs or fabless) who will make this in silico?