ARM Announces ARM v8-A with Scalable Vector Extensions: Aiming for HPC and Data Center
by Ian Cutress on August 22, 2016 4:37 AM EST
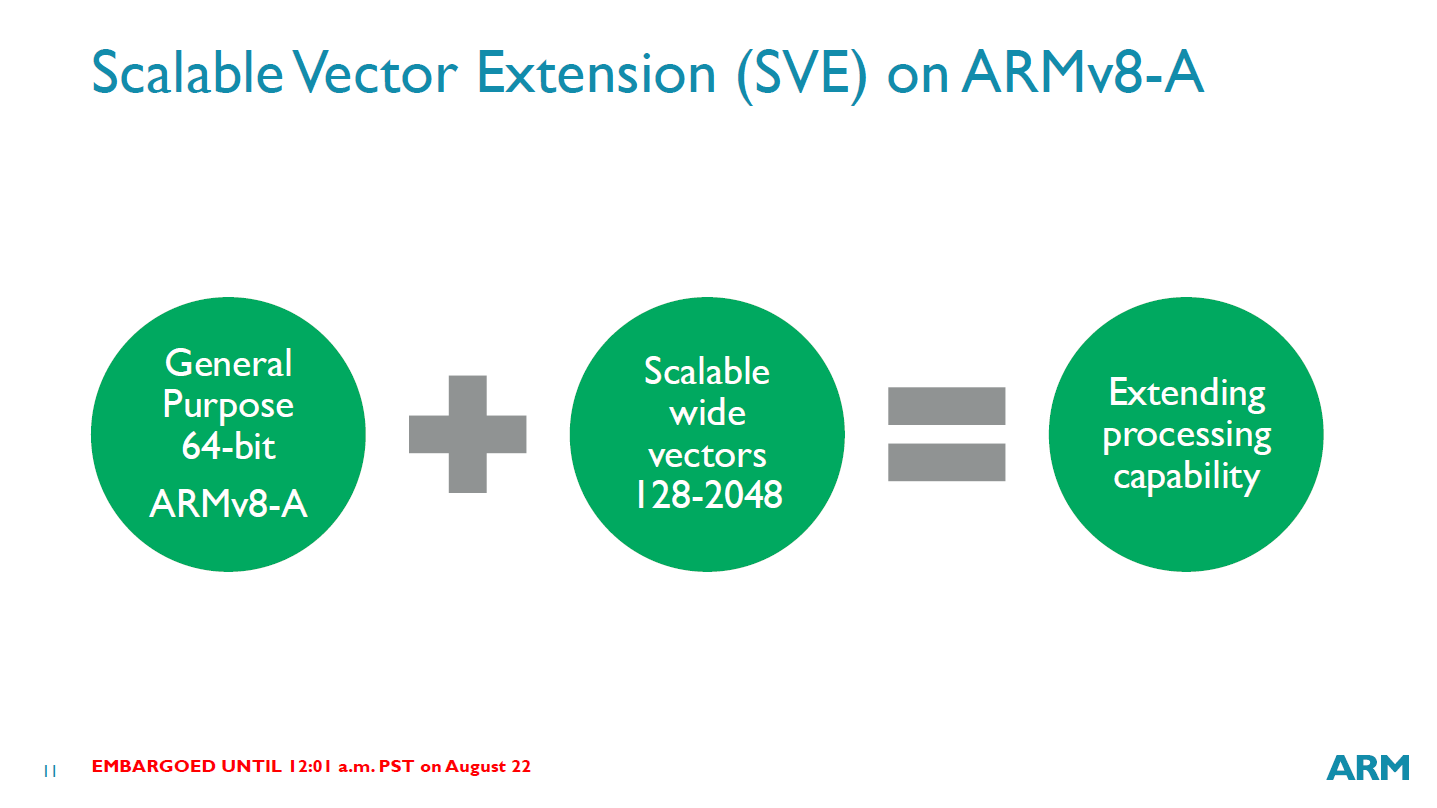
Today ARM is announcing an update to their line of architecture license products. With the goal of moving ARM more into the server, the data center, and high-performance computing, the new license add-on tackles a fundamental data center and HPC issue: vector compute. ARM v8-A with Scalable Vector Extensions won’t be part of any ARM microarchitecture license today, but for the semiconductor companies that build their own cores with the instruction set, this could see ARM move up into the HPC markets. Fujitsu is the first public licensee on board, with plans to include ARM v8-A cores with SVE in the Post-K RIKEN supercomputer in 2020.

Scalable Vector Extensions (SVE) will be a flexible addition to the ISA, and support from 128-bit to 2048-bit. ARM has included the extensions in a way that if included in the hardware, the hardware is scalable: it doesn’t matter if the code being run calls for 128-bit, 512-bit or 2048-bit, the scheduler will arrange the calculations to compensate for the hardware that is available. Thus a 2048-bit code run on a 128-bit SVE core will manage the instructions in such a way to complete the calculation, or a 128-bit code on a 2048-bit core will attempt to improve IPC by bundling 128-bit calculations together. ARM’s purpose here is to move the vector calculation problem away from software and into hardware.

This is different to NEON, which works on 64-bit and 128-bit vectors. ARM is soon submitting patches to GCC and LLVM to support the auto-vectorization for VSE, either by directives or detecting applicable command sequences.
Performance metrics performed in ARMs labs show significant speed up for certain data sets already and expect that over time more code paths will be able to take advantage of SVE. ARM is encouraging semiconductor architecture licensees that need fine-grained HPC control to adopt SVE in both hardware and code such that as the nature of the platform adapts over time both sides will see a benefit as the instructions are scalable.










15 Comments
View All Comments
MrSpadge - Monday, August 22, 2016 - link
At 1st glance this sounds a lot better than the mess Intel created with the different tiers of AVX 512, and which they are not yet implementing into regular CPUs anyway.And now someone please build an APU which uses the GPU execution units to execute those ultra-wide vector instructions (at fair latency) :)
OEMG - Monday, August 22, 2016 - link
Well compilers have dealt with messier parts of x86 for the last decades anyway. :)I have to give it to ARM though. The concept is cool. Though I slightly worry that this may actually induce more work for the compiler/programmer when it comes to optimizing for a specific chip/implementation as we all see implementation quirks such as false dependencies. They must get the scheduler right first and foremost.
Kevin G - Monday, August 22, 2016 - link
Optimization will require more work yes but getting code up and running shouldn't be more difficult. SVE also enables performance improvements with wider vector hardware with code targeting narrow units. On the x86 side of things, backwards compatibility is maintained with wider hardware but the additional width sits idle.From a programming standpoint, it almost makes more sense to always target 2048 bit wide vectors if the workload supports it. Granted there will be some overhead in splicing 2048 bit operations into smaller chunks vs. working with the hardware's native size. If the overhead is small (say <5%) that is a big win for both ARM and programmers.
You are correct though that a lot of this is dependent on getting the scheduler right.
YaleZhang - Monday, August 22, 2016 - link
Hiding the vector width from the programmer is great, but I don't expect that all instructions can be divided and conquered, especially the ones that operate horizontally, like SSE shuffle/permute, conflict detection (does ~N^2 comparisons), which have a non-linear cost w.r.t. vector width.Dmcq - Monday, August 22, 2016 - link
ARM seem in general to be more interested in designs which can operate across a wide range of performance levels and in standards and cutting costs down and an ecosystem of compilers and suchlike. I guess it is up to Fujitsu to make certain the grubbier bits needed for good performance are in the design as well.YaleZhang - Monday, August 22, 2016 - link
I forgot to emphasize that byte shuffles (_mm_shuffle_epi8() for SSE and VTBL for NEON) are very useful and used all the time for things like small lookup tables and data conversion. Intel never really extended this beyond 16 entry tables. I'm very interested to see how ARM will handle it. Anyone have the specs?Krysto - Monday, August 22, 2016 - link
Cool stuff. I do think ARM's arrival in the cloud computing space is inevitable, although it should happen pretty slowly (maybe only a little faster than Intel conquering the mainframe space over the span of a few decades).Unlike in the consumer space where Microsoft failed hard with Windows RT (even though they're trying to get back to arch-agnostic UWP apps) and where Google has a fetish for Intel chips in Chromebooks for NO GOOD REASON, in the server space, service providers don't have such a huge lock-in with "legacy architectures", so they can transition more easily to ARM.
That said, I hope ARM focuses more on security features going forward. They are needed for consumers, even more for cloud customers, and DIRELY needed for IoT, where ARM dominates right now. I don't feel like TrustZone is enough, especially when every OEM gets to use its own third-party closed source, full of bugs, "real time OS's" inside it. And by now there are better architectures, too, like Imagination's OmniShield, AMD's SEV, Intel SGX, and so on.
So far I've only read about a hardware security feature to protect against a certain class of bugs in ARMv8.1, and that's still years away. ARM is moving too slowly in this space. It needs to do a lot more, a lot faster. We don't want billions of insecure IoT devices flooding the market over the next 10 years, that can be exploited for the next 30 years because ARM doesn't think AGGRESSIVE security is that important of a feature to add to its chips right now.
TheinsanegamerN - Monday, August 22, 2016 - link
I kinda loke google putting an i7 in their chromebook, since I can throw ubuntu on it and play steam games. Nobody else makes a premium 12 inch laptop these days.But I agree that there should be more ARM based machines. My guess is that nobody will bother with them until someone makes a transition layer, similar to rosetta in osx 10.5, that allows x86 code to run on ARM. Until that happens, ARM will remain a niche market for years to come in non mobile.
Kevin G - Monday, August 22, 2016 - link
While legacy software will be an issue, that doesn't mean a vendor like Apple could come in and pull off a quick transition. A translation layer would be necessary but as quickly as they pulled off the PowerPC -> x86 transition, it'd only need to ship with MacOS for the first few years on ARM hardware.FunBunny2 - Monday, August 22, 2016 - link
"as quickly as they pulled off the PowerPC -> x86 transition"who 'they'? for Apple, it was a matter of re-compiling, since most of what they ship is in C/C++, and all such cpu these days have a compliant compiler. they do have to re-compile support libraries, too, since they generally target hardware specific code. again, for Apple not such a big deal since they hold most, if not all, of the relevant source. for those building apps for PPC Macs, I recall it was kinda a big deal.