Recovering Data from a Failed Synology NAS
by Ganesh T S on August 22, 2014 6:00 AM ESTRecovering the Data
Ubuntu + mdadm
After booting Ubuntu with all the four drives connected, I first used GParted to ensure that all the disks and partitions were being correctly recognized by the OS.

Synology's FAQ presents the ideal scenario where the listed commands work magically to provide the expected results. But, no two cases are really the same. When I tried to follow the FAQ directions, I ended up with a 'No arrays found in config file or automatically' message. No amount of forcing the array assembly helped.
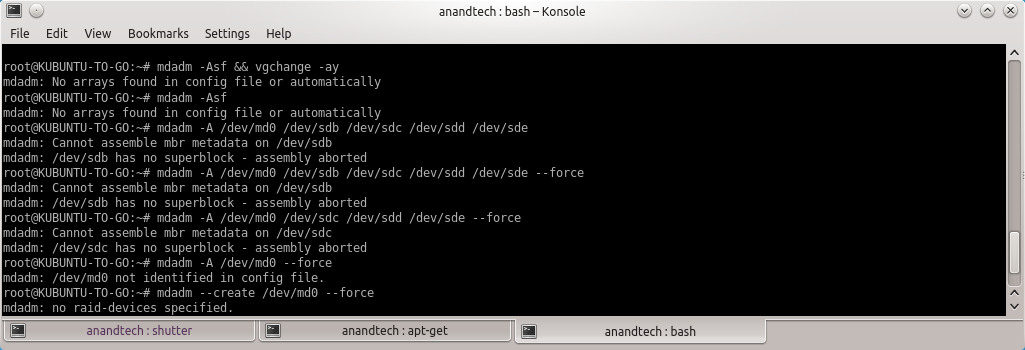
After a bit of reading up the man pages, I decided to look up mdstat and found that a md127 was actually being recognized from the Synology RAID operations. Unfortunately, all the drives had come up with a (S) spare tag. I experimented with some more commands after going through some Ubuntu forum threads.
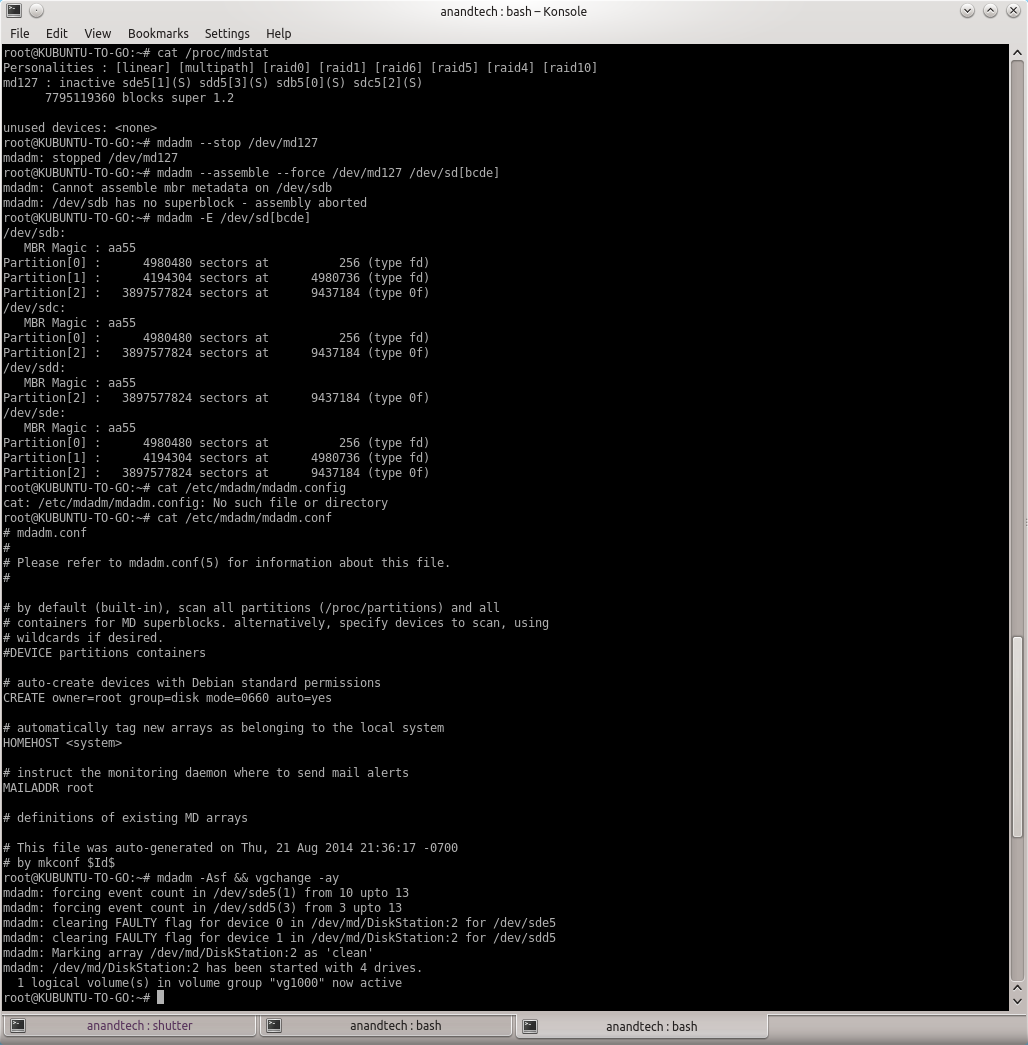
The trick (in my case) seemed to lie in actually stopping the RAID device with '--stop' prior to executing the forced scan and assemble command suggested by Synology. Once this was done, the RAID volume automatically appeared as a Device in Dolphin (a file explorer program in Ubuntu).
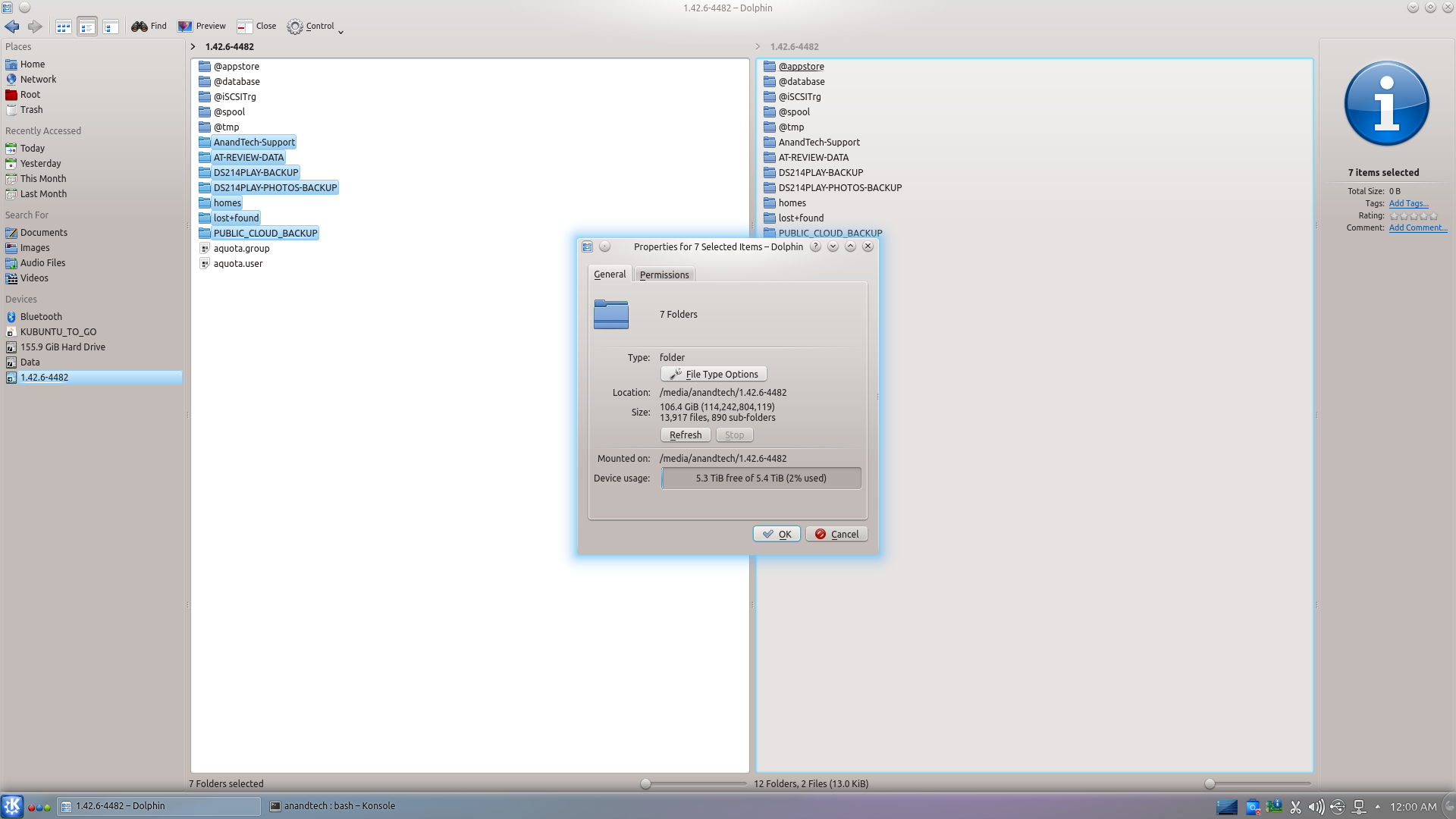
The files could then be viewed and copied over from the volume to another location. As shown above, the ~100 GB of data was safe and sound on the disks. Given the amount of time I had to spend searching online about mdadm, and the difficulties I encountered, I wouldn't be surprised if users short on time / little knowledge of Linux decide to go with a Windows-based solution even if it costs money.
Windows + UFS Explorer
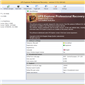
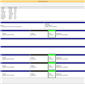
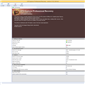
Prior to booting into Windows, I had all the four drives and the LaCie DAS connected to our DAS testbed. The four drives were recognized as having unknown partitions (thanks to most of them being in EXT4 format). However, that was not a problem for UFS Explorer. All the partitions in all the connected drives were recognized correctly and the program even presented the reassembled RAID-5 volume at the very end.
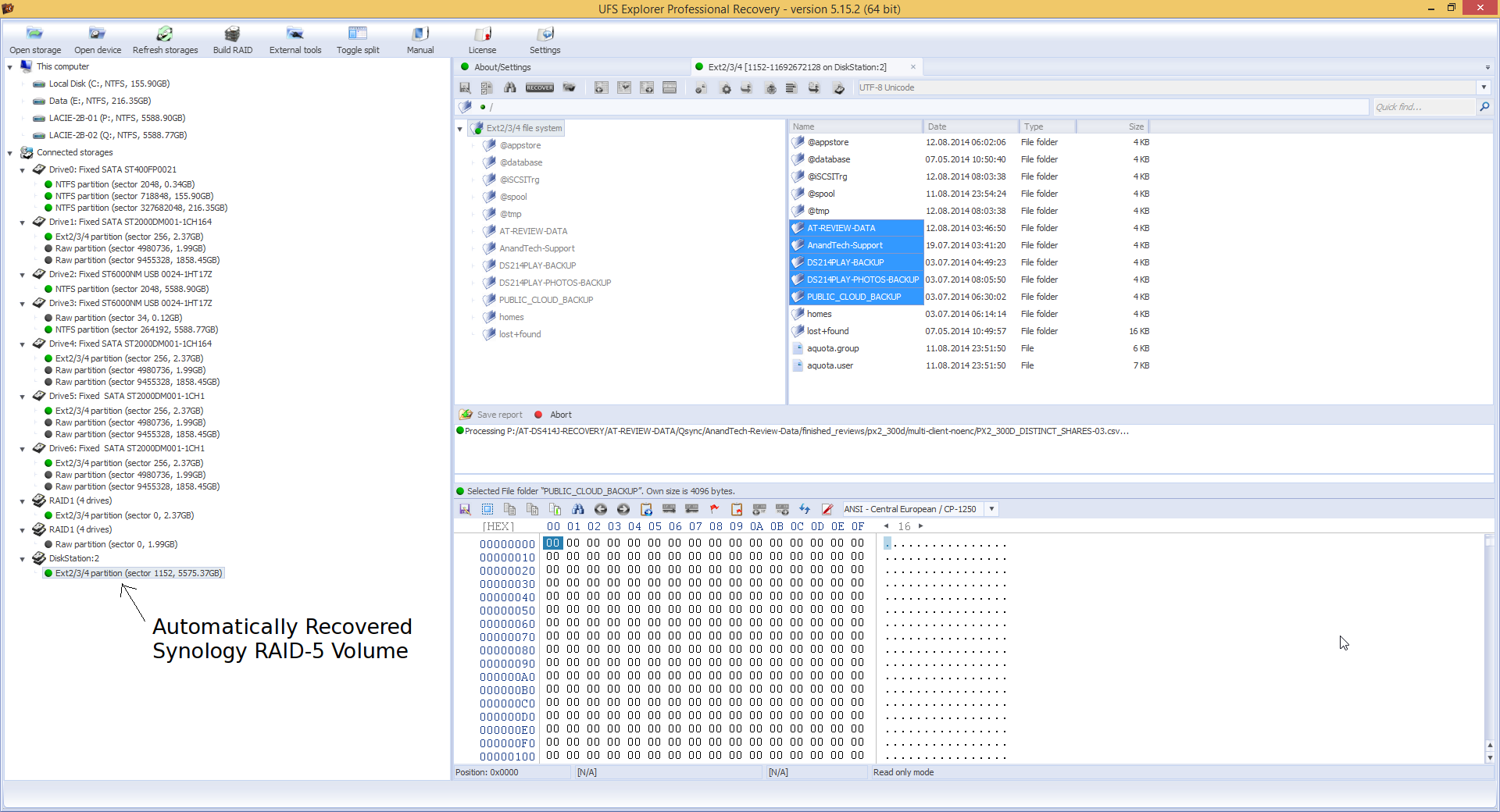
After this, it was a simple process of highlighting the appropriate folders in the right pane and saving it to one of the disks in the DAS.
Fortunately, I had only around 100 GB of data in the DS414j at the time of failure, and I got done with the recovery process less than 10 hours after waking up to the issue.








55 Comments
View All Comments
omgyeti - Friday, August 22, 2014 - link
Awesome article. I've had a DiskStation for over 3 years without any hiccups, but it's always nice to see an article with multiple recovery solutions presented in the event my luck takes a turn for the worse someday. I also back the NAS up to a USB drive, but don't want that to be my only hope in the event something ever happens.garrytaylo987 - Wednesday, June 6, 2018 - link
Issue related hard-disk are common so don't worry if you need a instant recovery of the data and partition, first try any free tool like mini tool that is secure,user-friendly and free. If the issue is not solved.t-rexky - Friday, August 22, 2014 - link
A very interesting read - thank you.I have DS1512+ with four 1 TB drives set-up using Synology Hybrid RAID and the fifth 3 TB drive holds a backup of the data. Coincidentally, I have been concerned about the backup integrity and I just had some discussions with Synology on the subject. The Synology Backup application cannot create a complete backup of my data because it skips all the symbolic links present in my data on the RAID volume. The only workaround at this point is to set up a cron job to use rsync for backup purposes as opposed to the Synology GUI backup application. Synology have promised to look into correcting this in the future, but right now the backups created by the DSM GUI are not complete.
Dahak - Friday, August 22, 2014 - link
Interesting article and a nice look at some possible ways to try to recover data.But I think that you got lucky as it was a hardware failure and not a drive failure, especially when you mentioned that the UFS Explorer automatically found the array.
Wonder if other people, as I am curious, may want to see how this would play out with a simulated drive failure, ie leave one of the drives off to simulate a failed / clicking drive.
DanNeely - Friday, August 22, 2014 - link
Ganesh already does do raid rebuild tests that simulate this.Dahak - Friday, August 22, 2014 - link
I do know that he does the raid rebuilds, but more a worse case scenario where the raid rebuild does not work due to some hardware issue and have to pull the drive and put them into another system.Although I know ideal that where your backups come in.
Flunk - Friday, August 22, 2014 - link
Compared to my experiences with low-end NAS units from other vendors this actually seems quite reasonable. It's the sort of thing that most enthusiasts or IT people could do without having to send it out for data recovery.icrf - Friday, August 22, 2014 - link
I set up a DS411j a few years ago with 2 TB Seagate drives in RAID 5 that's still working perfectly fine. I was explicit about RAID 5 because I had manually run arrays in mdadm for a while and noticed that's all it was when I logged into a shell on the NAS. I never had any doubt that if the NAS itself failed, but not the drives, that I could just plug them into another machine and have access to everything. It would never have crossed my mind to look for a Windows tool to access them. Having to stop an array that wasn't quite there before forcing it to show up probably would have taken me awhile to figure out, too.The worst that happened to me is when I had drives split between multiple SATA controller cards, and one of the controller cards flaked out and dropped half the drives in my RAID 5 array all at once. Since the array wasn't just degraded, it was down, there were no changes made. I just had to convince madam they weren't half spares. Calling madam --assume-clean was the ticket. You just have to get the order of the drives right when you pass in the devices else the file system is corrupt. You can stop and restart the array with another --assume-clean and another guess at order until the file system is valid without problem.
I love madam. Unfortunately, I also had a drive dying slowly with lots of bad sectors silently corrupting data for months. That led me to ZFS and data checksums, which are completely awesome. I'm not nearly as familiar with ZFS as I am with mdadm, so it makes me a little nervous. It also doesn't allow online capacity expansion, like mdadm. I think my next array is going to be a little more bleeding edge and use btrfs. Should be close to the best of both worlds.
Gigaplex - Saturday, August 23, 2014 - link
I agree with your sentiments about considering btrfs, however I'd advise against it for RAID5 equivalence for quite some time. Not only is it still considered experimental, it flat out isn't finished. Last I checked, it wasn't capable of automatically dropping a drive as it goes bad in parity mode.isa - Friday, August 22, 2014 - link
Great article. I think the two biggest issues were that the QSync app didn't do what you told it or expected it to do, and when it failed, the QSync app didn't tell you that it failed. hardware has come a long way in the past 15 years or so, but the robustness of backup/sync apps has not - we had apps that didn't do what we wanted many years ago.Given the vital importance of backup and sync apps to do what we expect them to do, app developers should spend much more effort with scripts or the like to set up backups more robustly, conduct self-tests of configs and settings to ensure settings will do what you expect, and better alert reporting if things occur that you don't expect. Put another way, you found out that your backup failed only when you needed it, which was exactly the SOTA 20 years ago. Disappointing (but not surprising) that it still may be for many users..