The Intel Core Ultra 7 155H Review: Meteor Lake Marks A Fresh Start To Mobile CPUs
by Gavin Bonshor on April 11, 2024 8:30 AM ESTASUS Zenbook 14 OLED UX3405MA: AI Performance
As technology progresses at a breakneck pace, so do the demands of modern applications and workloads. As artificial intelligence (AI) and machine learning (ML) become increasingly intertwined with our daily computational tasks, it's paramount that our reviews evolve in tandem. To this end, we have AI and inferencing benchmarks in our CPU test suite for 2024.
Traditionally, CPU benchmarks have focused on various tasks, from arithmetic calculations to multimedia processing. However, with AI algorithms now driving features within some applications, from voice recognition to real-time data analysis, it's crucial to understand how modern processors handle these specific workloads. This is where our newly incorporated benchmarks come into play.
Given makers such as AMD with Ryzen AI and Intel with their Meteor Lake mobile platform feature AI-driven hardware, aptly named Intel AI Boost within the silicon, AI, and inferencing benchmarks will be a mainstay in our test suite as we go further into 2024 and beyond.
The Intel Core Ultra 7 155H includes the dedicated Neural Processing Unit (NPU) embedded within the SoC tile, which is capable of providing up to 11 TeraOPS (TOPS) of matrix math computational throughput. You can find more architectural information on Intel's NPU in our Meteor Lake architectural deep dive. While both AMD and Intel's implementation of AI engines within their Phoenix and Meteor Lake architectures is much simpler than true AI inferencing hardware, these NPUs are more designed to provide a high efficiency processor for handling light-to-modest AI workloads, rather than a boost to overall inferencing performance. For all of these mobile chips, the GPU is typically the next step up for truly heavy AI workloads that need maximum performance.
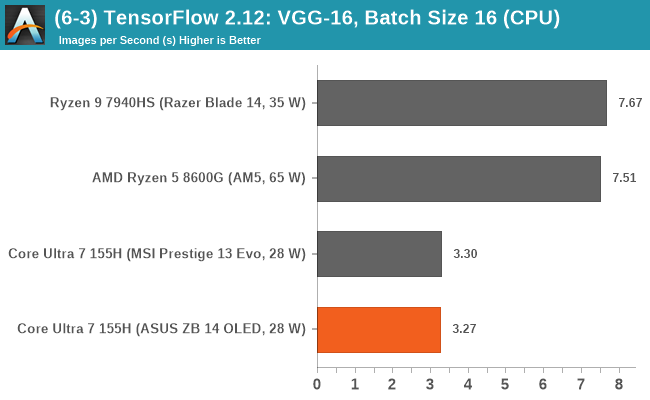
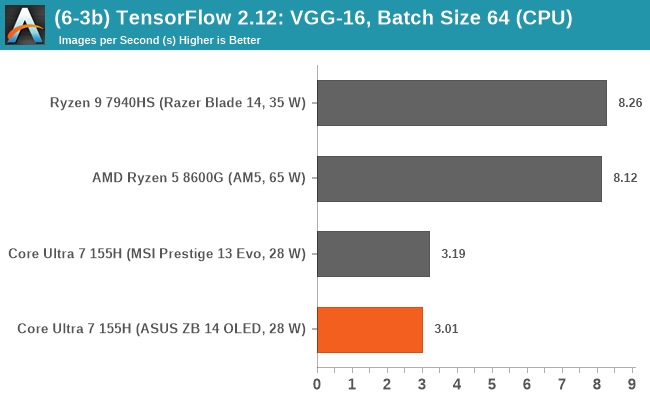
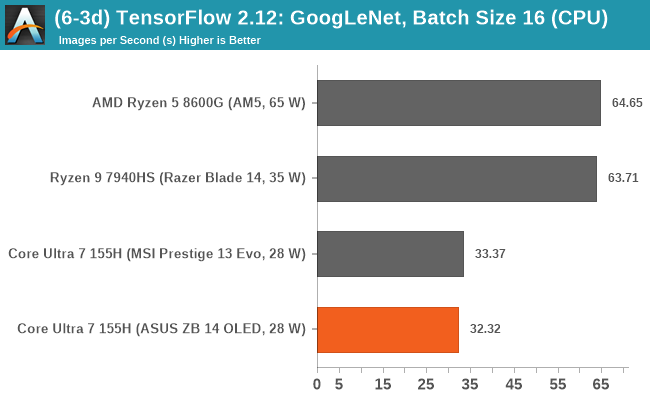
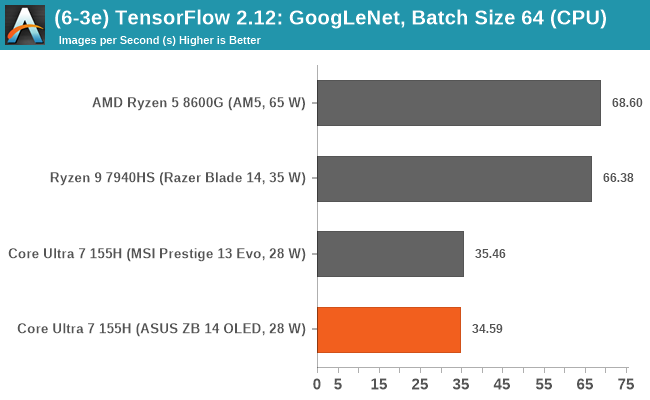
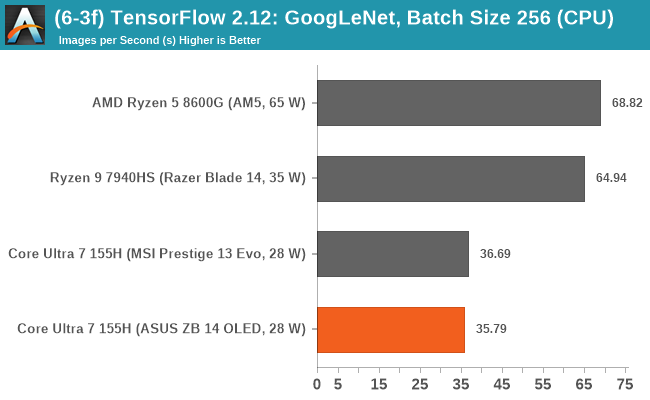
Looking at performance in our typical TensorFlow 2.12 inferencing benchmarks from our CPU suite, using both the VGG-16 and GoogLeNet models, we can see that the Intel Core Ultra 7 155H is no match for any of the AMD Phoenix-based chips.



Meanwhile, looking at inference performance on the hardware actually optimized for it – NPUs, and to a lesser extent, GPUs – UL's Procyon Computer Vision benchmark collection offers support for multiple execution backends, allowing it to be run on CPUs, GPUs, or NPUs. For Intel chips we're using the Intel OpenVINO backend, which enables access to Intel's NPU. Meanwhile AMD does not offer a custom execution backend for this test, so while Windows ML is available as a fallback option to access the CPU and the GPU, it does not have access to AMD's NPU.
With Meteor Lake's NPU active and running the INT8 version of the Procyon Computer Vision benchmarks, in Inception V4 and ResNet 50 we saw good gains in AI inferencing performance compared to using the CPU only. The Meteor Lake Arc Xe LPG graphics also did well, although the NPU is designed to be more power efficient with these workloads, and more often as not significantly outperforms the GPU at the same time.
This is just one test in a growing universe of NPU-accelerated appliations. But it helps to illustrate why hardware manufactuers are so interested in NPUs: they deliver a lot of performance for the power, at least as long as a workload is restricted enough that it can be run on an NPU.
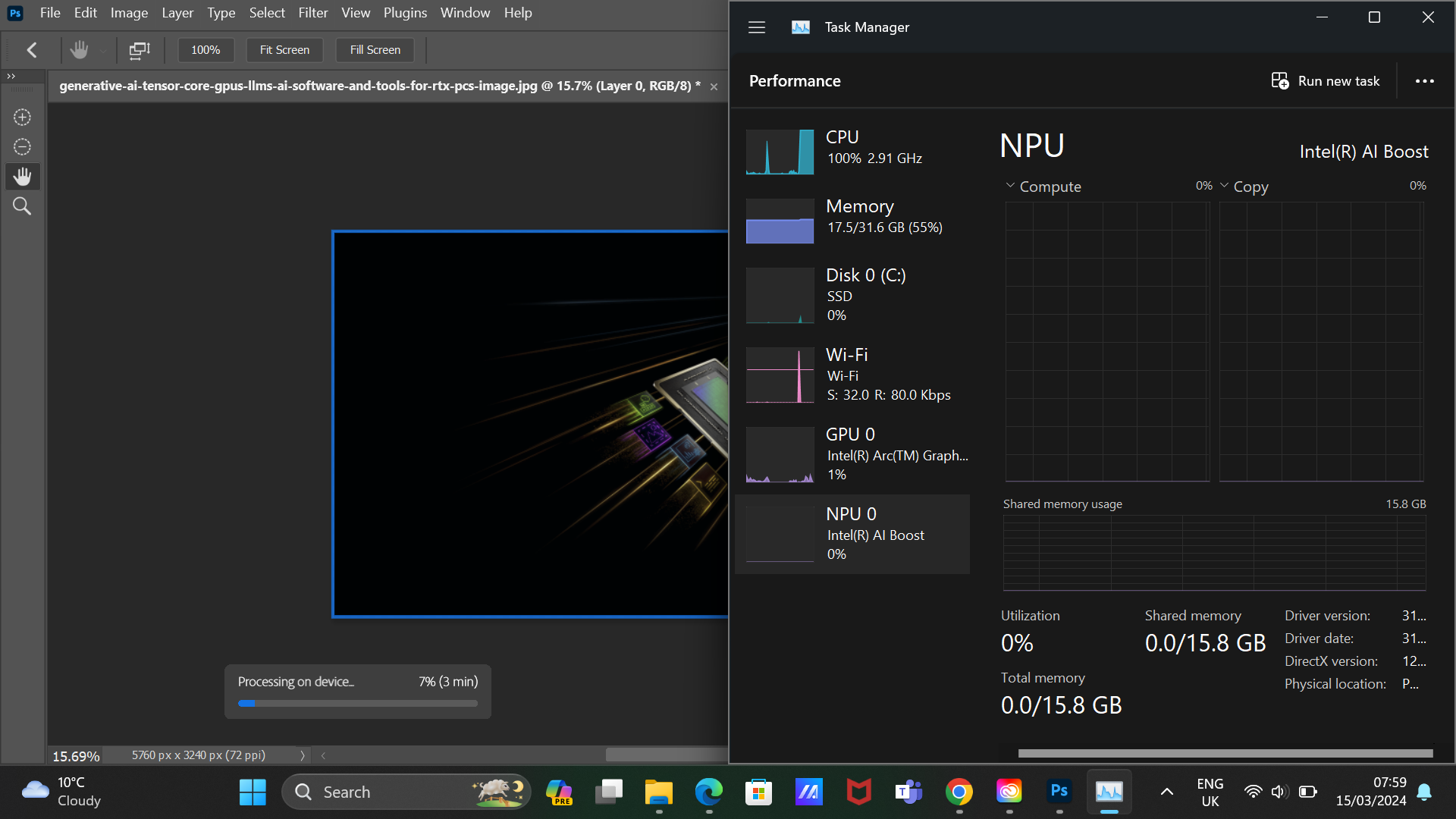
That all being said, even with the dedicated Intel AI Boost NPU within the SoC tile, the use case is very specific. Even trying generative AI within Adobe Photoshop using Neural fillers, Adobe was relying much more on the CPU than it was the GPU or the NPU, which shows that just because it's related to generative AI or inferencing, the NPU isn't always guaranteed to be used. This is still the very early days of NPUs, and even just benchmarking them for an active task remains an interesting challenge.








69 Comments
View All Comments
Dante Verizon - Thursday, April 11, 2024 - link
Too strange... in the spec2017 test that represents Blender MeteorLake wins but in the real Blender test it loses? GreatDante Verizon - Thursday, April 11, 2024 - link
The iGPU performance of desktop APUs is also abnormally low.Gavin Bonshor - Friday, April 12, 2024 - link
Could you please elaborate? Did another publication's results land higher? Did they run JEDEC memory settings?ballsystemlord - Thursday, April 11, 2024 - link
That near 50% increase in DRAM access latency coupled with the higher thermal limitations is probably what's holding the 115H back.Ryan Smith - Thursday, April 11, 2024 - link
Keep in mind that they're different workloads with different versions of Blender. The version in SPEC2017 is from 7 years ago, which was the Blender 2.7 era.mode_13h - Monday, April 15, 2024 - link
spec2017 is using an old version of Blender that's frozen in time. That's needed to make all spec2017 results comparable with each other.In the individual Rendering benchmarks, Gavin used a reasonably current version of Blender (3.6 is a LTS release from June 27, 2023), probably also built with a different compiler.
Hulk - Thursday, April 11, 2024 - link
"AMD Arc" in GPU specs?Gavin Bonshor - Friday, April 12, 2024 - link
Yeah, that was a really weird one. It has since been corrected.Fozzie - Thursday, April 11, 2024 - link
Why is the text seemingly out of line with the actual results? Repeatedly it is describing wins for the U7 155H that don't seem to be backed up in the actual benchmarks. For example:"As we can see from our rendering results, the Intel Core Ultra 7 155H is very competitive in single-threaded performance and is ahead of AMD's Zen 4 mobile Phoenix-based Ryzen 9 7940HS."
Actually, the graphs don't show a single instance of the Ultra 7155H besting the Ryzen 9 7940HS in ALL of the preceding graphs.
"Looking at performance in our web and office-based testing, in the UL Procyon Office-based tests using Microsoft Office, the Core Ultra 7 155H is actually outperforming the AMD Ryzen 9 7940HS, which is a good win in itself."
How is 6,792 greater than 7,482? How is 6,978 higher than 7,162?
Did the benchmarks get updated after the text was written? Did someone write the summary text and not pay attention to "Higher is better" vs "Lower is better"?
phoenix_rizzen - Thursday, April 11, 2024 - link
The text describing the Spec tests are also incorrect."Even though the Core Ultra 7 155H is technically an SoC, it remains competitive in the SPECint2017 section of our single-thread testing against the Ryzen 9 7940HS. The AMD chip performs better in two of the tests (525.x264_r and 548.exchange2_r); on the whole, Intel is competitive."
Except the graph shows the AMD system beating the Intel system in 7 tests and only losing by a small margin in 3 of them. The AMD system even beats the Intel desktop system in 4 tests and ties it in 1.
"In the second section of our single-threaded testing, we again see a very competitive showing in SPECfp2017 between the Intel Core Ultra 7 155H and the AMD Ryzen 9 7940HS. The only test we see a major gain for the Ryzen 9 7940HS is in the 503.bwaves_r test, which is a computational fluid dynamics (CFD) simulation."
Except the AMD system wins in 4 tests, essentially ties in 5 tests, and only loses in 2. It even beat the desktop system in 3 tests.
The text is nowhere near consistent with the graphs.