Original Link: https://www.anandtech.com/show/2596
Lucid's Multi-GPU Wonder: More Information on the Hydra 100
by Derek Wilson on August 22, 2008 4:00 PM EST- Posted in
- GPUs
So, lots of people were asking really good questions about Lucid and their Hydra engine after we posted the initial story on it. We had the opportunity to sit down with them and ask some of those and other questions. And they had quite a lot of really interesting things to say.
From a mile high and the promise of hardware not this year but next, it is tough to really get a good understanding of exactly what's going on and what the implications of this hardware could be if they can deliver on what they say they can. We'll do our best to explain what we know and also what the pitfalls could be.
First, let's address the issue of the box we showed off in the previous coverage. No it will not need an external device. Lucid has designed this to be solution that can be dropped onto a motherboard or a graphics card so integration and user experience should be seamless.
This would be even more transparent than SLI and CrossFire because not even an internal bridge would be needed. Just plug any two cards from the same vendor (and i think they also need to use the same driver version though this is less than clear) and performance will scale linearly with the capabilities of each card.
They did mention the fact that they can implement a solution in an external box for notebooks. For those who need something portable but want high end graphics at home, they could just attach the graphics cards linked with a Hyrda 100 (via PCIe over cables) to the notebook. Not ideal, but it still offers some advantages over high end internal cards (especially in the area of heat) that you might not need when you're on the road.
Sound too good to be true? Yes. Did we see it working? Sure. Do we have performance numbers? Not yet. So there's the rub for us. We really want to put this thing through its paces before we sign off on it. Running on both UT3 and Crysis (DX9 only for now -- DX10 before the product ships though) is cool, but claiming application agnostic linear scaling over an arbitrary number of GPUs of differing capability is a tough pill to swallow without independent confirmation.
We asked them for hardware, and we really hope they'll get us some sooner rather than later. They seemed interested in letting us test it as well. Even if we can't publish numbers on it, it would go a long way for us being more excited about the product if we could run our own benchmarks on it just to see for ourselves.
Let's Talk About Applications
Obviously it'll accelerate games. What about GPGPU? That's not the focus of Lucid right now. They said they want to look at the largest market for the part and target that first, and gaming is certainly where that is at. It is physically possible that the hardware and software could load balance other tasks across the hardware, but this isn't something that is currently being explored or developed.
It will also accelerate games using multiple GPUs while outputting to multiple displays. Imagine 4 GPUs sharing the load over 3 monitors for a flight sim. Neither NVIDIA nor AMD can pull something like this off right now with their technology.
This can end up on both GPUs and on motherboards, and they can be cascaded. There is a limit to how many you can cascade because you will start introducing latency (but Lucid didn't define that limit). But 1 level deep is reasonable apparently. And this means it seems like it would be possible (except for the power requirements) to build a motherboard with 4 slots that had 4 cards each with 2 GPUs (let's say GTX 280s) connected by a Hyrda 100 chip.
And if scaling is really linear, 8x GTX 280 would certainly deliver way more than we could possibly need for a pretty good while. We'd be CPU and system limited until the cows come home (or at least a good 2 or 3 generations of hardware out into the future). Well, either that or developers would catch on that they could allow ridiculous features to be enabled for the kind of super ultra mega (filthy rich) users that would pick up such a crazy solution.
Upgrading hardware would be stupidly simple. Forget PhysX or anything like that: leave your older card in the system and upgrade to the latest generation and they'll both contribute equally to the rendering of frames (and since graphics is usually the largest bottleneck in the system, this will improve performance more than any other solution anyway). If we added a GTX 280 to a card with half it's performance, we'd see a 50% performance improvement over a single GTX 280. Not bad at all. There would be less downside in buying a high end part because it could continue to serve you for much longer than usual. And low end parts would still contribute as well (with a proportionally smaller gain, but a gain nonetheless).
Lucid also makes what seems like a ridiculous claim. They say that in some cases they could see higher than linear scaling. The reason they claim this should be possible is that the CPU will be offloaded by their hardware and doesn't need to worry about as much so that overall system performance will go up. We sort of doubt this, and hearing such claims makes us nervous. They did state that this was not the norm, but rather the exception. If it happens at all it would have to be the exception, but it still seems way too out there for me to buy it.
Aside from utterly invalidating SLI and CrossFire, this thing opens up a whole realm of possibilities. If Intel adopts it for their high end motherboards, they would have the ultimate solution for gaming. Period. If it's up to board vendors, chipset will still be less relevant in at least multi-GPU performance than the inclusion or exclusion of the Lucid Hydra 100.
But can they really do it? And how do they even attempt to do it? They've told us a little bit, and we'll brainstorm a bit and see what we can come up with.
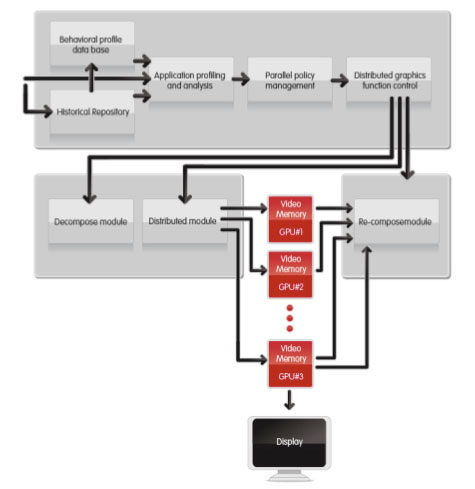
What Does This Thing Actually Do?From a high level, Lucid's technology intercepts DirectX or OpenGL API calls, analyzes them, organizes them into distinct tasks, and based on the analysis combined with the historical performance of various cards handling of previous frames' workload, it evenly distributes the tasks across all the GPUs in the system.
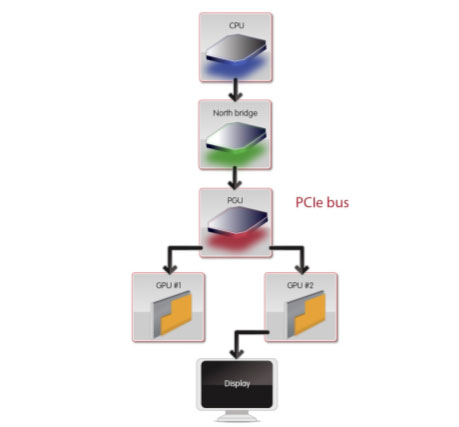
After the workload is distributed, the buffers are read back to the Hydra chip and composited before the final scene is sent to the proper graphics card for display. Looking a bit deeper, here is a block diagram of the process itself from Lucid's whitepaper.
The current implementation can take x16 PCIe in and can switch it to either 2x x16 PCIe channels or up to 4x x16 PCIe channels. This gives it support for 1 to 4 cards depending on how the motherboard or graphics card handles things. They do have the flexibility to scale down to x8 in and 2x x8 out, making lower cost motherboards feasible as well. Future products may support more graphics cards and more PCIe lanes, but right now 4 is what makes sense. Lucid says the hardware can scale up to any number of cards with linear performance improvement.
Some of the implications of this process are that if any graphics card in the system has other work being done on it (say maybe physics or video or something), the load will be dynamically balanced and you'll still be able to squeeze as much juice out of all the hardware in your system as possible. Pretty cool huh? If it works as advertised that is.
The demo we saw behind closed doors with Lucid did show a video playing on one 9800 GT while the combination of it and one other 9800 GT worked together to run Crysis DX9 with the highest possible settings at 40-60 fps (in game) with a resolution of 1920x1200. Since I've not tested Crysis DX9 mode on 9800 GT I have no idea how good this is, but it at least sounds nice.
Since Lucid is analyzing the data, they can even do things like not draw hidden "tasks" (if an entire object is occluded, rather than send it to a graphics card, it just doesn't send it down). I asked about dependent texturing and shader modification of depth, and apparently they also build something like a dependency graph and if something modified affects something else they are able to adjust that on the fly as well.
In theory, tracking and adjusting to dependencies on the fly will completely avoid the issues that keep NVIDIA and AMD from running AFR in all games. And they even claim that this can help give you higher than linear scaling when using their hardware with more than one card.
We asked what the latency of their implementation is, and they said it is negligible. Of course, that's not a real answer, especially for guys like us who want to know the details so we can understand what's going on better. We don't just want to see the end result, we want to know how we get there. Playing Crysis didn't feel laggy, but there is no way this solution doesn't introduce processing time.
An explanation for this is the fact that the Hydra software can keep requesting and queuing up tasks beyond what graphics cards could do, so that the CPU is able to keep going and send more graphics API calls than it would normally. This seems like it would introduce more lag to us, but they assured us that the opposite is true. If the Hydra engine speeds things up over all, that's great. But it certainly takes some time to do its processing and we'd love to know what it is.
Moving Machine Code Around
Lastly, there is another elephant in the room. It takes in API calls, but what does it send out to the GPUs? It can't send the hardware itself API calls, cause it doesn't know what to do with these. It must send machine code generated by the graphics driver. So all the difficult analysis of API calls and grouping of tasks and load balancing has to happen in software in the driver.
We really don't have any idea how this would work in the real world, but it seems like they'd have to send batches of either tagged or timed API calls to the driver and tell their chip which GPU is going to get the set. The silicon would then send the newly generated machine code down the pipe to the appropriate driver until it was told otherwise or something. And of course, the chip would also request and composite the pixel data and send it back to the display device.
But that would have to have a CPU load right? We really want and need more details before we can truly understand what is happening in this software and hardware combination. It is absolutely certain though, that the only practical way to do this is for the hardware itself to be switching machine code rather than API calls. And since the hardware also has almost no memory, it can't be doing analysis either.

The progression has to be: game -> Hydra software -> graphics card driver -> Hydra 100 hardware -> multiple graphics cards. Managing this seems like it would be a bit cumbersome, and it seems like they'd have to either set register on the hardware to tell it which direction to send the next set of commands or they would have to embed something in the commands being sent to the GPUs that would help the hardware figure out where to send the data. Or maybe it can trick the graphics driver into thinking the destination of the one graphics card it is rendering to changes multiple times in a frame. We don't know, but we really want to.
We do also get the added benefit that it offers a dedicated set of two x16 PCIe lanes to graphics hardware. This means that it can be very efficient in handling the data movement between the two and it can do full up and downstream communication with both at the same time. Since it doesn't have a memory, to composite the frame, it needs to do two reads and then a write while its doing the next two reads. It's gotta keep things moving. Which it can do very quickly and efficiently with all the PCIe lanes available to it and both graphics cards.
Also note that this really does dedicate all the graphics resources available (memory, geometry, pixel, etc.) to the processing of the scene. Each card even sees full PCIe x16 bandwidth (when the Hydra 100 is talking to it anyway), and the switching back and forth can actually act as another way to hide latency (one card continues to process data while the other is receiving and then back again).
Barriers to Entry and Final Words
Depending on the patents Lucid has, neither NVIDIA nor ATI may be able to build a competing bit of hardware / software for use in their own solutions. And then there is the quesetion: what will NVIDIA and ATI attempt to do in order to be anticompetitive (err, I mean to continue to promote their own solutions to or platforms surrounding multi-GPU).
Because of the fact that both NVIDIA and ATI already participate in anti-competitive practices by artificially limiting the functionality of their hardware on competing platforms, it doesn't seem like a stretch to think they'll try something here as well. But can they break it?
Maybe and maybe not. At a really crappy level they could detect whether or not the hardware is in the system and refuse to do anything 3D. If they're a little nicer they could detect whether the Hydra driver is running and refuse to play 3D while it is active. Beyond that it doesn't seem like there is really much room to do anything like they've been doing. The Lucid software and hardware is completely transparent to the game, the graphics driver and the hardware. None of those components need to know anything for this to work.
As AMD and NVIDIA have to work closely with graphics card and motherboard vendors, they could try and strong arm Lucid out of the market by threatening either (overtly or not) the supply of their silicon to certain OEMs. This could be devastating to Lucid, as we've already see what the fear of an implication can do to software companies in the situation with Assassin's Creed (when faced with the option of applying an already available fix or pulling support for DX10.1 which only AMD supports, they pulled it). This type of thing seems the largest unknown to us.
Of course, while it seems like an all or nothing situation that would serve no purpose but to destroy the experience of end users, NVIDIA and ATI have lots of resources to work on this sort of "problem" and I'm sure they'll try their best to come up with something. Maybe one day they'll wake up and realize (especially if one starts to dominate over the other other) that Microsoft and Intel got slammed with antitrust suits for very similar practices.
Beyond this, they do still need to get motherboard OEMs to place the Hydra 100 on their boards. Or they need to get graphics hardware vendors to build boards with the hardware on them. This increases cost, and OEMs are really sensitive to cost increases. At the same time, a platform that can run both AMD and NVIDIA solutions in multi-GPU configurations has added value. As does a single card multi-GPU solution that gets better performance than even the ones from AMD and NVIDIA.
The parts these guys sell will still have to compete in the retail market, so they can't price themselves out of competition. More performance is great, but they have to worry about price/performance and their own cost. We think this will be more attractive to high end motherboard vendors than anyone else. And we really hope Intel adopts it and uses instead of nForce 100 or nForce 200 chips to enable flexible multi-GPU. Assuming it works of course.
Anyway, Lucid's Hyrda 100 is a really cool idea. And we really hope it works like Lucid says it will. Most of the theory seems sound, and while we've seen it in action, we need to put it to the test and look hard at latency and scaling. And we really really want to get excited. So we really really need hardware.






