Intel Opens D1X-Mod3 Fab Expansion; Moves Up Intel 18A Manufacturing to H2’2024
by Ryan Smith on April 11, 2022 1:00 PM EST
Intel for the last few years has been undergoing a major period of manufacturing expansion for the company. While the more recent announcements of new facilities in Ohio and Germany have understandably taken a lot of the spotlight – especially given their importance to Intel’s Foundry Services plans – Intel has been working even longer on expanding their existing facilities for their own use. The company’s development of next-generation EUV and Gate-All-Around-style transistors (RibbonFET) not only requires creating and refining the underlying technology, but it also just flat out requires more space. A lot of it.
To that end, Intel today is holding a grand opening in Oregon for the Mod3 expansion of D1X, the company’s primary development fab. The expansion, first announced back in 2019, is the third such mod (module) and second expansion for Intel’s main dev fab to be built since D1X’s initial construction in 2010. And in keeping with tradition for Intel fab launches and expansions, the company is making something of an event of it, including bringing Oregon’s governor out to show off their $3 Billion investment.

But fanfare aside, the latest mod for the fab is a genuinely important one for Intel: not only does it add a further 270,000 square feet of clean room space to the facility – expanding D1X by about 20% – but it’s the only fab module that’s big enough to support the High Numerical Aperture (High NA) EUV tool that Intel will be using starting with its 18A process. ASML’s forthcoming TWINSCAN EXE:5200 EUV tool is designed to be their most powerful yet, but it’s also quite a bit larger than the NXE 3000 series EUV tools Intel is using for their first generation EUV processes (Intel 4/Intel 3). It’s so big that D1X’s ceiling is too low to fit the machine, never mind the floor supporting its weight.

Size Comparison: ASML Normal & High NA EUV Machines
As a result, Mod3 has been built, in no small part, to fit this massive machine. Intel isn’t expecting to take delivery of the machine for a couple more years, but they had to start preparations years in advance just to get to this point.
Meanwhile, although D1X-Mod3 is only being officially declared open today, Intel has already been moving critical tools into Mod3 since last August. Consequently, today’s opening is something of a ceremonial launch for the mod, as parts of it are already setup (if not already in use). Still, even with that head start, according to Intel the company expects to be moving in tools for another year, especially as they bring in the remaining, lower-priority tools.
Coincidentally, our own Dr. Ian Cutress had a chance to see D1X in all of its glory late last year, when he toured the facility. At the time Intel was already in the final stages of finishing the Mod3 expansion, as well as bringing up EUV machines as part of the development of the Intel 4 and Intel 3 process nodes, Intel’s first EUV nodes. So for more information on D1X and what goes on there, be sure to check out that article.

A line of EUV machines at D1X
Finally, along with formally opening the Mod3 expansion, Intel today is also using the opportunity to rename the 450-acre campus that D1X sits on. Intel’s Ronler Acres campus has been the center of Intel’s fab R&D efforts for decades, and along with D1X, also houses Intel’s older D1 development fabs, such as D1B, D1C, and D1D. So, in reflection of all of the important R&D that goes on at the site, Intel is renaming it after co-founder Gordon Moore, one of the instrumental figures behind the development of Intel’s earliest technologies. The newly renamed campus will now go by Gordon Moore Park at Ronler Acres, or Gordon Moore Park for short. And despite the many (many) things that have been named after Moore over the years, from laws and buildings to awards and medals, this is the largest thing named after Moore (yet), as it’s the first time a whole campus has been named after the luminary.
Intel Roadmap Update: Intel 18A Moved Up to H2 2024
Alongside briefing the press about the D1X-Mod3 opening, Intel also used their latest press event to get everyone up to speed on the latest updates on Intel’s development roadmap. Strictly speaking, nothing here is new – all of this was first announced during Intel’s 2022 Investor Meeting back in February. However this is the first time Intel has engaged the technical press, rather than investors, on the current state of its development efforts.
The big news here is that Intel is formally moving up the start date for manufacturing on the Intel 18A node. Intel’s second-generation “angstrom” node was originally expected in 2025; but now the company is bumping that up by half a year, to the second half of 2024.
As a result, Intel’s roadmap now looks like this:
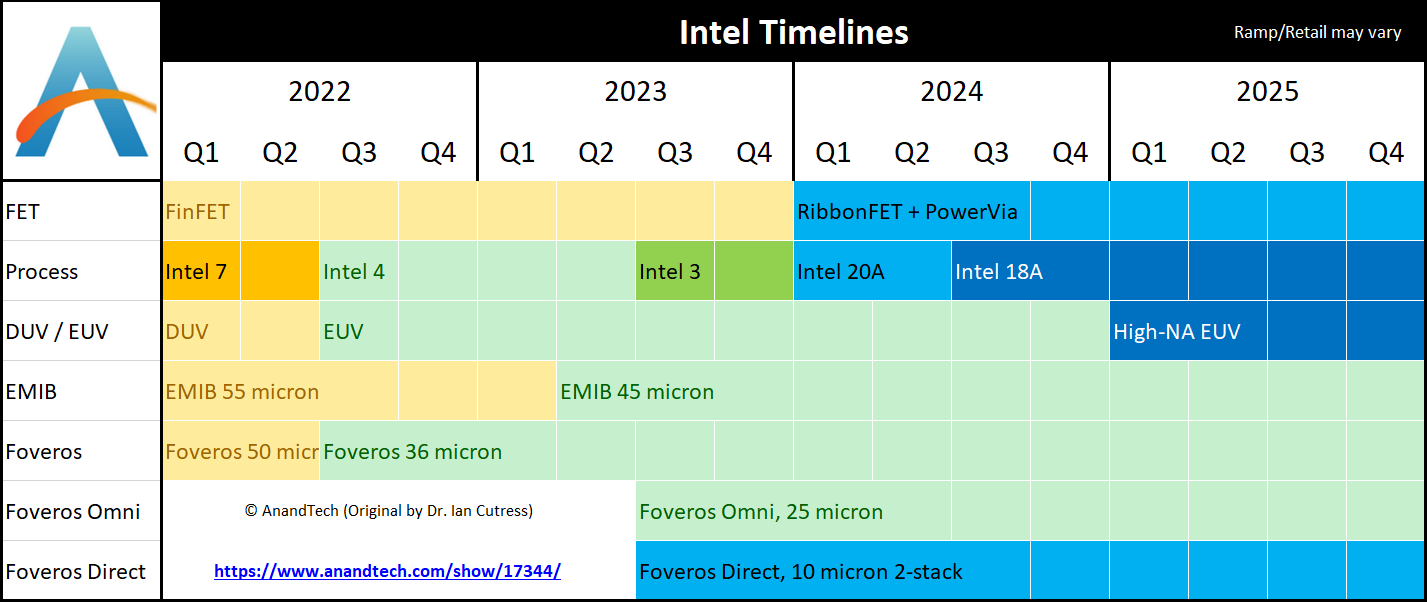
With the company already gearing up for its first EUV process, Intel 4, later this year, Intel’s roadmap starts looking very compressed beginning in the second half of 2023. The second half of that year will see Intel 3 go into production, which is Intel’s enhanced EUV process. Meanwhile, potentially as soon as 6 months after that, Intel 20A goes into production. 20A is Intel’s first “angstrom” node, which incorporates their gate-all-around-style “RibbonFET” FinFets, as well as PowerVias.
But, if all goes according to plan, 20A will seemingly be a relatively short-lived node due to the movement of 18A. Intel’s second-generation angstrom node, which will incorporate an updated ribbon design and other improvements to Intel’s GAA manufacturing technology. Since 18A remains the farthest node out on Intel’s manufacturing roadmaps, the company is remaining relatively mum on everything new that 18A will entail, but it remains the point where Intel plans to re-establish unquestioned leadership of the chip making industry.
According to Intel, 18A development has been moving so well that the company’s R&D operations are now on or ahead of all of their development milestones, giving the company confidence that they can begin manufacturing products based on the process node in late 2024, instead of 2025 as first planned.
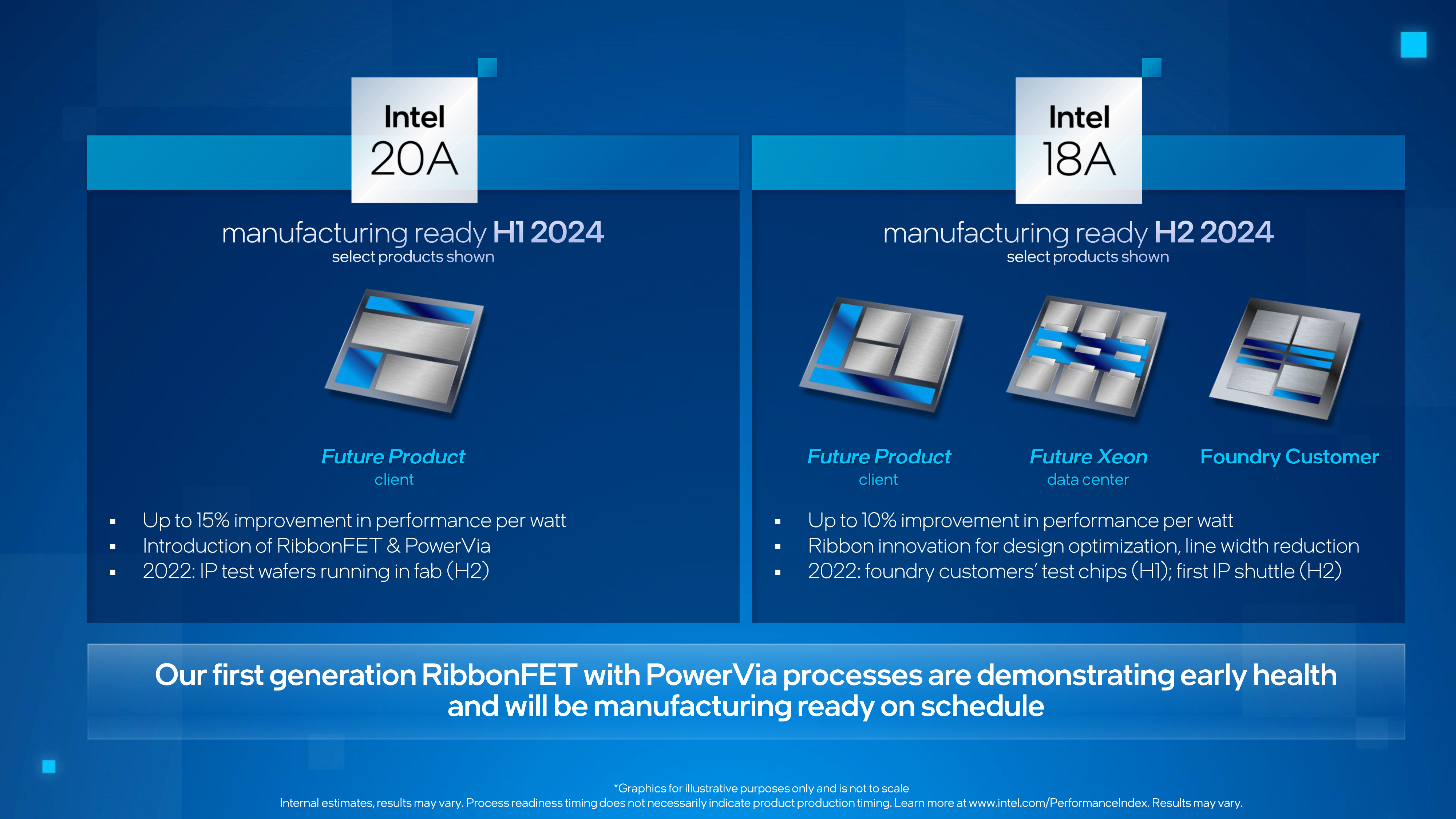
One consequence of bringing in 18A, however, is that it means Intel is now definitely going into initial production of 18A without all of their High NA machines. 18A remains the process node where High NA machines will debut, but as the TWINSCAN EXE 5200 is still not expected to be in place until 2025, that means Intel will now have to use their existing 3000 series machines to kickstart 18A production. Until this latest development, Intel had been presenting High NA machines and 18A as being tied at the hip, so whether that was always the actual case or not, now that is clearly not the case.
What that means for 18A production, in turns, remains to be seen. Since Intel can use their normal (non-HA) machines for 18A, then presumably the biggest advantages of the High NA machines were throughput, allowing Intel to process wafers with little (or not) multi-patterning thanks to High NA’s greater accuracy. Seemingly, the most likely outcome is that Intel will be able to produce 18A in 2024, and maybe even in decent volumes, but that they won’t be able to go into Intel-scale high volume manufacturing until the first High NA machine is available in 2025.
And, as always, it should be noted that Intel’s manufacturing roadmap dates are the earliest dates that a new process node goes into production, not the date that hardware based on the technology hits the shelves. So even if 18A launches in H2’24 as it’s now scheduled, it could very well be a few months into 2025 before the first products are in customer hands, especially if Intel launches in the later part of that window. All of which, given the large size of these launch windows and Intel’s own history, is a likely bet, as Intel has rarely launched new products/technologies early in a release window.
Finally, Intel’s development briefing also included confirmation that Intel is employing a purely internal “test risk reduction” node as part of their development process for their PowerVia technology. The purpose of the test node is to decouple the full risk of 20A by allowing Intel to develop and test PowerVias separately from RibbonFETs. In this case, the test node uses Intel’s well-established FinFET technology on the front-end, while employing a test version of PowerVia on the backend. No such node has been announced for RibbonFETs, but even if one doesn’t exist, not having to debug first-generation PowerVia on 20A alongside the RibbonFETs is still a simplification of the process, as it allows Intel to pursue both elements semi-independently, and learn from both of them in the process.

This is a significant change from how Intel has developed major new manufacturing nodes in the past, and even they are the first to admit as such. Intel’s 10nm problems were caused in large part by bundling too many technology changes together all at once, combined with a very aggressive reduction in feature size. Separating these things into smaller, more frequent manufacturing node updates was one way Intel is mitigating this risk in the future. And now with an internal test node for PowerVia development, they’re aiming to do even more risk mitigation in order to be able to roll out both RibbonFETs and PowerVia together in the first half of 2024 as part of Intel 20A.












89 Comments
View All Comments
mode_13h - Wednesday, April 13, 2022 - link
> Look at how Apple dialed BACK the number of E-cores for M1 Pro and Max.Apples and Oranges, I say. Apple's P-cores are a lot more efficient than Intel's, so Apple probably doesn't have to worry about thermal throttling with the number they were willing to pack onto the Pro and Max dies. And it's not like they have so many P-cores, either. Where E-cores really come into their own is when you start to scale to even higher core counts.
> And E-core probably has a useful role in the data center for servers whose primary
> job is to move data around with minimal manipulation thereof
Intel's E-cores aren't *that* weak. Gracemont is about 65% as fast at integer workloads as Golden Cove (both, single-thread), in Alder Lake. Once you scale up core counts, the P-cores would have to run at lower clocks, thereby narrowing the gap further.
Also, Sapphire Rapids will introduce special-purpose "DSA" engines for simple data movement tasks.
> a possible direction E-cores could go, ... a sea of generic throughput computing.
> This is essentially the bet that Tenstorrent (Jim Keller's new crowd) are making.
Tenstorrent's cores are very special-purpose and infused with dedicated SRAM. That makes it a poor candidate for insight into general computing trends.
> it's hard for generic compute to compete against specialized HW
> once the problem domain is well-enough specified...
No, they're targeting generic computing tasks with their E-cores, and providing a range of other solutions for special-purpose workloads. Everything from on-die AMX to Altera FPGAs, GPUs, and Habana's & Movidius' AI accelerators.
> for Intel to launch, say 8P- + 24E-cores is a hell of a bet
Agreed. It's hard to see the need for that much concurrency, in a mainstream desktop platform. You're right that we'd need a minor software revolution to put them all to good use. I have some ideas about how the programming model would have to shift, and it represents a significant departure from industry standard techniques, at both the user space and kernel level. That's obviously not going to happen in a mere couple of years.
> Transputers
I loved reading about them, back in the early 90's. Then, I had to program arrays of SHARC DSPs, their spiritual descendant, and it pretty much sucked. But, that had a lot to do with there being no global memory, not to mention cache coherence. So, the connection to modern E-cores is tenuous at best.
ccNUMA didn't really come onto the scene until after that.
mode_13h - Wednesday, April 13, 2022 - link
> Intel's E-cores aren't *that* weak. Gracemont is about 65% as fast at integer workloads> as Golden Cove (both, single-thread), in Alder Lake.
In fact, if we compute IPC by naively dividing each by their respective single-core turbo speeds, Gracemont rises to 86% of Golden Cove's IPC.
Source: https://www.anandtech.com/show/17047/the-intel-12t...
Calin - Wednesday, April 13, 2022 - link
"It remains unclear that E-core is a great match for the desktop."If by "desktop" you mean several (4-8) cores running hardly parallelizable workloads, then an E-core might be quite useful in laptops (with low energy use means both saving "direct use" electricity and "no cooling fans" electricity). Also, not using much of the power budget means that a performance core will have a lot more headroom for the couple of seconds it might be needed.
Also, E-cores will be quite useful if you can launch lots and lots of threads (video processing, some engineering applications, ...).
But, if what you need is gaming (or similar performance profiles), then 4-8 big cores are all that you need.
mode_13h - Wednesday, April 13, 2022 - link
> if what you need is gaming ... then 4-8 big cores are all that you need.Yes, but not for the reasons you state. Games can scale graphics a lot more easily than they can scale what the CPU is mostly doing. Because of that, games tend to end up with a narrower window of CPU requirements than GPU requirements (i.e. in terms of relative performance). So, even if a game engine *could* find enough useful work to keep 32 E-cores busy, doing so would mean those gamers with a mere quad core CPU would be out of luck.
> E-cores will be quite useful if you can launch lots and lots of threads (video processing
Yes, though video processing is best done on GPUs.
I think a sea of E-cores would be great for building large software packages, however. That already scales well to CPUs with 32-cores and above.
whatthe123 - Wednesday, April 13, 2022 - link
they didn't really dial back e cores. they had few performance cores to start with and only upped core counts to match competition. their cores are already smaller than the competition as well thanks to the node advantage so there's no need to improve performance/area.it's when you get to parity that the performance/area benefits come into play, but Apple pays more to get early access to next gen nodes so there's no way to compare designs directly until other designers are on the same node. they also control their whole software stack so you can't even compare performance figures as they vary wildly depending on compatibility with the M1.
mode_13h - Wednesday, April 13, 2022 - link
> they also control their whole software stack> so you can't even compare performance figures
> as they vary wildly depending on compatibility with the M1.
No, they don't control the apps. And there are some compute-intensive apps with native versions for both M1 and x86 (on both Apple and other platforms).
I think the reason Apple didn't scale E-cores is that for lower core-counts, it's more important to have P-cores. Just look at the Alder Lake desktop product stack. Once you have about 8 P-cores, you reach a point where any more cores is about increasing throughput rather than reducing latency. And that's where E-cores shine.
I'd imagine Mac Pro could do something like pairing 16 or 32 P-cores with 64 or 128 E-cores. I think it'd be cute if they'd put the Ultra on a PCIe card and use it as a dGPU. What does the Ultra have for PCIe connectivity?
Jp7188 - Wednesday, April 13, 2022 - link
I think you're being generous to imply Intel chose not to use more than 8 P cores. I'd say they are forced to keep it to 8 or less for power and thermal reasons on the consumer platform where they are forced to run on the wrong side of the frequency curve in order to compete. Likewise I see the hybrid design as being forced on them to compete on both single and multi thread fronts. Without that they wouldn't have been relevant in the mid to upper range this generation.mode_13h - Thursday, April 14, 2022 - link
> Intel .. are forced to keep (P-cores) to 8 or less for power and thermal reasonsThey absolutely *could* have used more P-cores, but the power & thermal limits would've meant decreasing the all-core clock speeds. And, at that point, the performance margins would've tilted even more in favor of E-cores.
Whether you look at perf/W or perf/area, E-cores are simply a better way to scale performance to highly-threaded workloads. I haven't seen any credible argument against that. The main concerns seem to be about impacts on thread scheduling - particularly as it pertains to more lightly-threaded workloads.
drothgery - Tuesday, April 12, 2022 - link
And by "garbage BGA trash" you mean the U series CPUs that power a large majority of shipping PCs and have for quite a long time now?Diogene7 - Monday, April 11, 2022 - link
I would be curious to know if there is any update on when Intel plan using spintronics (especially MRAM, SOT-MRAM) as Persitent Memory in High Volume Manufacturing (HVM) ?I wish so much to see new innovation spurring from MRAM cache and, ideally as DRAM replacement in SoC, maybe for Qualcomm 18A SoC…
It would bring the possibility to create new « always-on / normally off » innovative chips / products…