The Intel Lakefield Deep Dive: Everything To Know About the First x86 Hybrid CPU
by Dr. Ian Cutress on July 2, 2020 9:00 AM ESTLakefield: Top Die to Bottom Die
At the top is the compute die, featuring the compute cores, the graphics, and the display engines for the monitors.

It might be easier to imagine it as the image above. The whole design fits into physical dimensions of 12 mm by 12 mm, or 0.47 inch by 0.47 inch, which means the internal silicon dies are actually smaller than this. Intel has previously published that the base peripheral interposer silicon is 92 mm2, and the top compute die is 82 mm2.
Compute Die
Where most of the magic happens is on the top compute die. This is the piece of silicon built on Intel’s most advanced 10+ nm process node and contains the big core, the small cores, the graphics, the display engines, the image processing unit, and all the point-to-point connectivity. The best image of this die looks something like this:

The big block on the left is the Gen 11 graphics, and is about 37% of the top compute die. This is the same graphics core configuration as what we’ve seen on Intel’s Ice Lake mobile CPUs, which is also built on the same 10+ process.
At the top is the single Sunny Cove core, also present in Ice Lake. Intel has stated that it has physically removed the AVX-512 part of the silicon, however we can still see it in the die shot. This is despite the fact that it can’t be used in this design due to one of the main limitations of a hybrid CPU. We’ll cover that more in a later topic.
At the bottom in the middle are the four Tremont Atom cores, which are set to do most of the heavy lifting (that isn’t latency sensitive) in this processor. It is worth noting the relative sizes of the single Sunny Cove core compared to the four Tremont Atom cores, whereby it seems we could fit around three Tremont cores in the same size as a Sunny Cove.
On this top compute die, the full contents are as follows:
- 1 x Sunny Cove core, with 512 KiB L2 cache
- 4 x Tremont Atom cores, with a combined 1536 KiB of L2 cache between them
- 4 MB of last level cache
- The uncore and ring interconnect
- 64 EUs of Gen11 Graphics
- Gen11 Display engines, 2 x DP 1.4, 2x DPHY 1.2,
- Gen11 Media Core, supporting 4K60 / 8K30
- Intel’s Image Processing Unit (IPU) v5.5, up to 6x 16MP cameras
- JTAG, Debug, SVID, P-Unit etc
- LPDDR4X-4267 Memory Controller
Compared to Ice Lake mobile silicon, which measures in at 122.52 mm2, this top compute die is officially given as 82.x mm2. It’s worth noting that the Ice Lake die also contains what Lakefield has on the base die as well. This top die has been quoted as having 4.05 billion transistors and 13 metal layers. For those playing a transistor density game at home, this top die averages 49.4 million transistors per square millimeter.
Base Die / Interposer Die
The base interposer die is, by contrast, a lot simpler. It is built on Intel’s 22FFL process, which despite the name is actually an optimized power version of Intel’s 14nm process with some relaxed rules to allow for ultra-efficient IO development. The benefit of 22FFL being a ‘relaxed’ variant of Intel’s own 14nm process also means it is simpler to make, and really chip by comparison to the 10+ design of the compute die. Intel could make these 22FFL silicon parts all year and not break a sweat. The only complex bit comes in the die-to-die connectivity.

The small white dots on the diagram are meant to be the positions of the die-to-die bonding patches. Intel has quoted this base silicon die as having 10 metal layers, and measuring 92.x mm2 for only only 0.65 billion transistors. Again, for those playing at home, this equates to an average density of 7.07 million transistors per square millimeter.
On this bottom die, along with all the management for the die-to-die interconnects, we get the following connectivity which is all standards based:
- Audio Codec
- USB 2.0, USB 3.2 Gen x
- UFS 3.x
- PCIe Gen 3.0
- Sensor Hub for always-on support
- I3C, SDIO, CSE, SPI/I2C

One element key to the base interposer and IO silicon is that it also has to carry power up to the compute die. With the compute die being on top to aid in the cooling configuration, it still has to get power from somewhere. Because the compute die is the more power hungry part of the design, it needs dedicated power connectivity through the package. Whereas all the data signals can move around from the compute die to the peripheral die, the power needs to go straight through. As a result, there are a number of power oriented ‘through silicon vias’ (TSVs) that have to be built into the design of the peripheral part of the processor.

Power and High Speed IO
Here’s a more complex image from a presentation earlier this year. It shows that Intel is using two types of connection from the bottom die to the top die: signal (data) connections and power connections. Intel didn’t tell us exactly how many connections are made between the two die, stating it was proprietary information, but I’m sure we will find out in due course when someone decides to put the chip in some acid and find out properly.
However, some napkin math shows 28 power TSV points, which could be in any of the configurations to the right – those combinations have a geometric mean of 3.24 pads per point listed, so with 28 points on the diagram, we’re looking at ~90 power TSVs to carry the power through the package.
Normally passing power through a horizontal or vertical plane has the potential to cause disturbance to any signalling nearby – Intel did mention that their TSV power implementations are actually very forgiving in this instance, and the engineers ‘easily’ built sufficient space for each TSV used. The 22FLL process helped with this, but also the very low density of the process needed gave plenty of room.
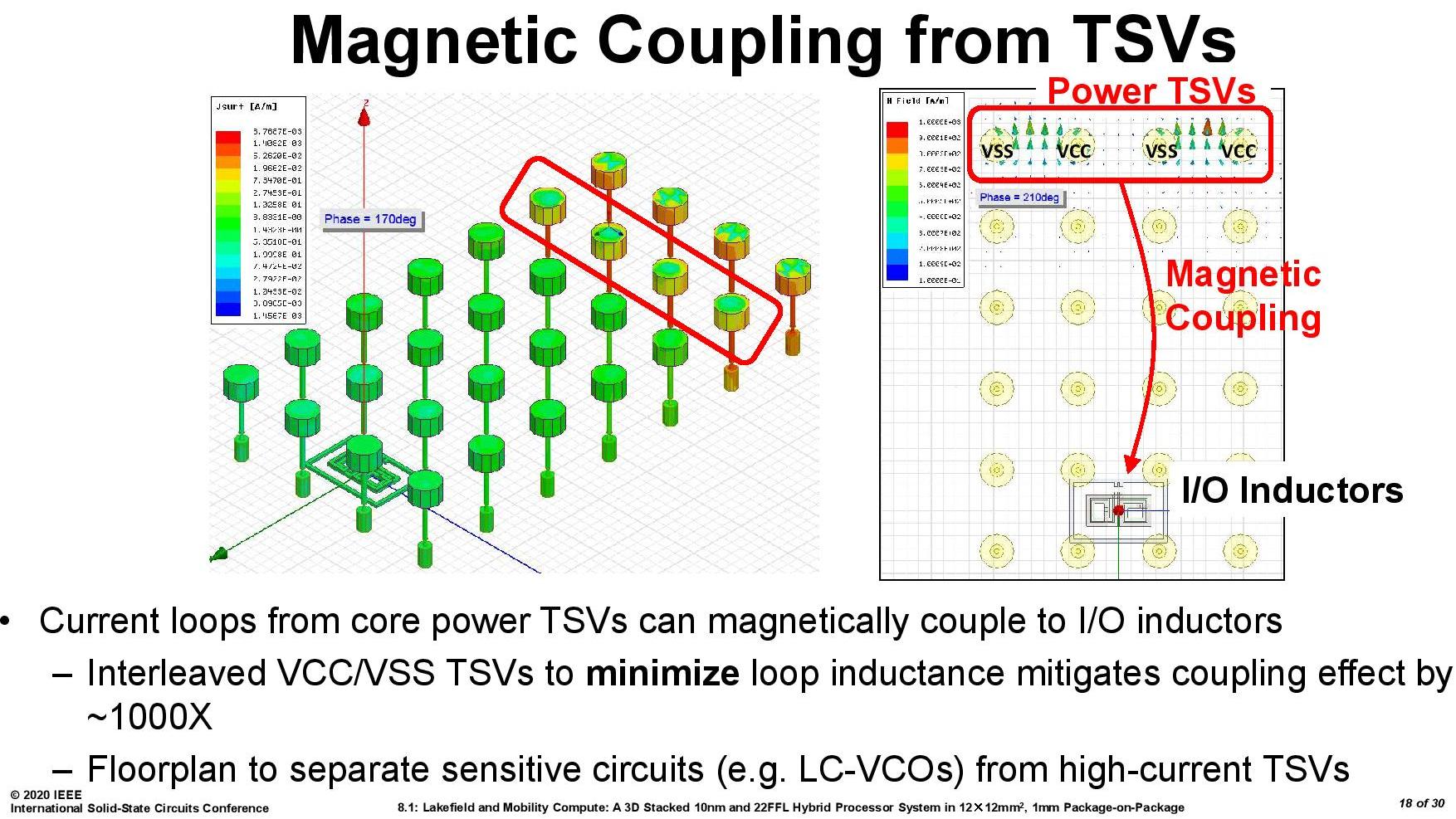
From this slide we can see that the simulations on TSVs in the base die required different types of TSV to be interleaved in order to minimize different electrical effects. High current TSVs are very clearly given the widest berth in the design.
When it comes to the IO of the bottom die, users might see that PCIe 3.0 designation and baulk – here would be a prime opportunity for Intel to announce a PCIe 4.0 product, especially with a separate focused IO silicon chiplet design. However, Lakefield isn’t a processor that is going to be paired with a discrete GPU, and these PCIe lanes are meant for additional peripherals, such as a smartphone modem.
Not to be discouraged, Intel has presented that it has looked into high-speed IO through its die-to-die interconnect.
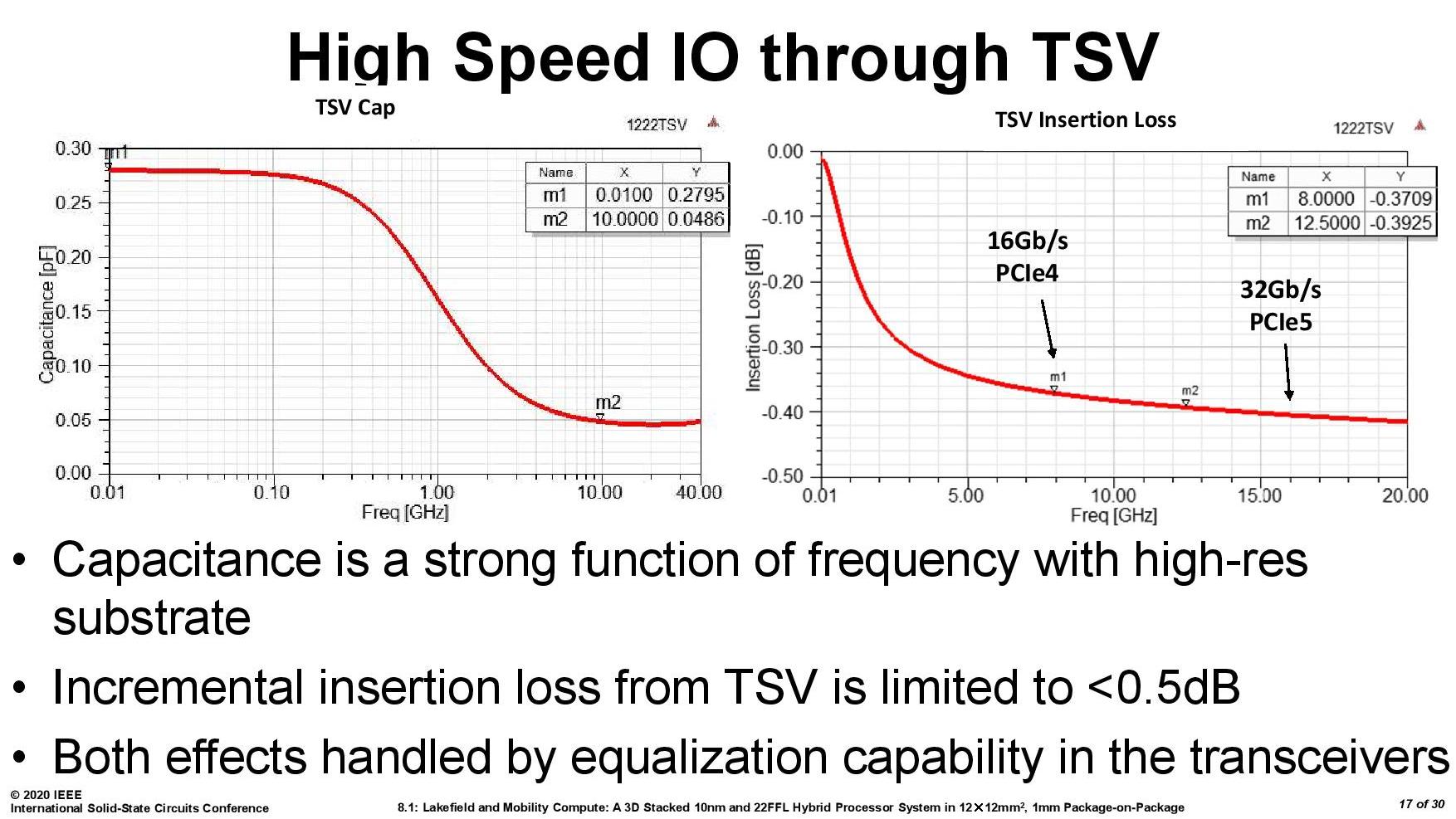
In this case, Intel battles capacitance as the higher frequency requirements of newer PCIe specifications. In this instance the signal insertion loss difference between PCIe 4.0 and PCIe 5.0 is fairly low, and well within a 0.5 dB variance. This means that this sort of connectivity might see its way into future products.
Memory
Also built into the package is the onboard memory – in this case it is DRAM, not any form of additional cache. The PoP memory on top (PoP stands for Package on Package) comes from a third party, and Intel assembles this at manufacturing before the product is sold to its partners. Intel will offer Lakefield with 8 GB and 4 GB variants, both built on some fast LPDDR4X-4266 memory.
In our conversations with Intel, the company steadfastly refuses to disclose who is producing the memory, and will only confirm it is not Intel. It would appear that the memory for Lakefield is likely a custom part specifically for Intel. We will have to wait until some of our peers take the strong acids to a Lakefield CPU in order to find out exactly who is working with Intel (or Intel could just tell us).
The total height, including DRAM, should be 1 mm.

As mentioned earlier in the article, Intel moving to chiplets one on top of the other exchanges the tradeoff of package size for one of cooling, especially when putting two computationally active parts of silicon together and then a big hunk of DRAM on top. Next we’ll consider some of the thermal aspects to Lakefield.








221 Comments
View All Comments
Quantumz0d - Sunday, July 5, 2020 - link
PC gaming marketcap is supposed to be at $40Bn by 2022, total gaming market is $120Bn including everything, and Consoles are built on AMD x86 technology and now DX12U and you think that is a niche ?ARM is not going to do anything just because Apple did, there are so many trials by so many companies and the best company which is known for it's ROI with R&D, Qualcomm abandoned all of it's Server ARM marketshare dreams with the death of their full custom Centriq. x86 runs blazingly fast and optimized with Linux which is what the world is powered just because ARM is good in thin and light garbage doesn't make it a superstar.
ARM is not going to get into Desktop at all, no one is going to write their programs again to suppor that HW, and no company is going to invest in DIY market before Server/DC market. Supercomputer market is not the DIY or Enterprise, look at the Top Supercomputers, Chinese Tianhe and 2 positions are with Chinese only, AMD CRAY Zen based IF supercomputer is about to come as well.
Wilco1 - Sunday, July 5, 2020 - link
The #1 supercomputer is Arm, and Arm servers beat x86 servers on performance, cost and power, so not a single "fact" in your post is correct.lmcd - Sunday, July 5, 2020 - link
That first statement is hilariously disconnected from the second. Fugaku at 3x the cost per flop of its next competitor hardly backs up your assertion.ARM servers might beat x86 servers on performance, cost, and power but it's not looking that good vs x86_64. The latter arch is commodity hardware, software, and talent hiring.
Wilco1 - Monday, July 6, 2020 - link
Just looking at the peak FLOPS in comparisons is deceiving. Fugaku is a very different design as it does not use GPU accelerators like most supercomputers. That means it is far better than the rest in terms of ease of programming and efficiency. So even if the upfront cost is higher, they expect to get far more out of it than other super computers.I'd say Arm servers are doing really well in 2020, clearly companies want a change from the x86 duopoly. Much of the talent is at companies that do Arm designs. How else do you think Arm CPUs are getting 20-30% faster per year, and mobile phones already outperform the fastest x86 desktops?
Quantumz0d - Tuesday, July 7, 2020 - link
No company wants to develop an in house IP, that R&D and ROI is not easy, Amazon did it because to chop off some costs and set up a plan for the low end AWS instances with Graviton 2, Altera is still yet to show, Centriq abandoned by Qcomm with so much of marketing done around Cloudflare and top class engineering work, the team which made 820's full custom core.AND What the fuck you are babbling on fastest x86 desktops (Like Threadripper 3990X, or 3950X, 10900K) outperformed by mobile phones ? Ooof, you are gulping down the AT's SPEC scores aren't you ?
ARM servers LMAO, like how AMD upped their DC marketshare with EPYC7742, dude stop posting absolute rubbish. ARM marketshare in data centers is in 0.5% area where IBM also resides.
Quantumz0d - Monday, July 6, 2020 - link
Tiahu is fucking Chinese Sunway Processor based Supercomputer and it's top #3 so what did they do ? jack off to Zen with Hygon or did they make all Chinese use Chinese made processors ? Stop that bullshit of Supercomputer nonsense, IBM has been there since ages and they had SMT8 with Power9 uarch which came in 2017 (Summit which is #2, it was first since 2018) what did they do ? x86 is consumer based and DC market is relying only on that. ARM DC market-share is less than fucking 2%, AMD is at 4.5%, Intel is at 95% that is 2019 Q4.I don't know why people hate x86 as if it's like their life is being threatened by them, the fact that x86 machines are able to run vast diverse rich software selection and more freedom based computing, people want ARM based proprietary dogshit more, Apple series trash wich their APIs or the Bootloader locked (much worse like chastity) or Unlocked Android phones, even with GNU GPL v2 and Qcomm's top OSS CAF the godddamned phones do not get latest updates or anything but a Core2Quad from decade ago can run a fucking Linux or Win7 / Win10 without any bullshit issue.
Wait for the SPEC A series iPhone 12 benchmarks and then you be more proud of that garbage device which cannot compute anything outside what Apple deems it.
Wilco1 - Friday, July 3, 2020 - link
It would be good to run benchmarks on the 2 variants of Galaxy Book S. One comparison I found:https://browser.geekbench.com/v5/cpu/compare/25848...
So Lakefield wins by only 21% on single-threaded (that's a bad result given it is Cortex-A76 vs IceLake at similar clocks), and is totally outclassed on multithreaded...
lmcd - Sunday, July 5, 2020 - link
Current scheduler doesn't even guarantee that's the Sunny Cove core.Wilco1 - Monday, July 6, 2020 - link
Given Tremont can't get anywhere near Cortex-A76 performance, we can be sure single-threaded result is the Sunny Cove core.PaulHoule - Friday, July 3, 2020 - link
This is an example of the "Innovator's Dilemma" scenario where it is harder to move upmarket (in terms of performance) than downmarket.Put a phone processor into a box with a fan and people will be blown away by how fast it is -- they've never seen an ARM processor cooled by a fan before.
Put a desktop processor into a thin tablet with little thermal headroom and people will be blown away by how slow it is.
So first it is a situation that Intel can't win, but second it is a disaster that this low performance (downmarket) chip is expensive to produce and has to be sold upmarket. Sure you can stick any number of dies together and "scale up" a package in a way that looks as if you scaled up the chip by reducing the feature size, but when you reduce the feature size the cost per feature goes down in the long term -- when you stick a bunch of cheap chips together you get an expensive chip.