Western Digital Stuns Storage Industry with MAMR Breakthrough for Next-Gen HDDs
by Ganesh T S on October 12, 2017 8:00 AM ESTScaling Hard Drive Capacities
Hard disk drives using magnetic recording have been around for 60+ years. Despite using the same underlying technology, the hard drives of today look nothing like the refrigerator-sized ones from the 1960s. The more interesting aspect in the story is the set of advancements that have happened since the turn of the century.
At a high level, hard disks are composed of circular magnetic plates or 'platters' on which data is recorded using magnetization and the patterns of magnetization represent the data stored. The patterns are laid out in terms of tracks. They are created, altered and recognized with the help of 'heads' mounted on an actuator that perform read and write operations. Modern hard disks have more than one platter in a stack, with each platter using its own individual 'head' to read and write.
There are additional hardware components - the motor, spindle, and electronics. The segment of interest from a capacity perspective are the platters and the heads. The slide below shows two ways to increase the capacity of a platter - increasing the number of tracks per inch (TPI) and/or increasing the number of bits per inch (BPI) in a single track. Together they yield a metric for areal density, which the industry gives as a value in bits per square inch, such as gigabits per square inch (Gb/in2) or terabits per square inch (Tb/in2).
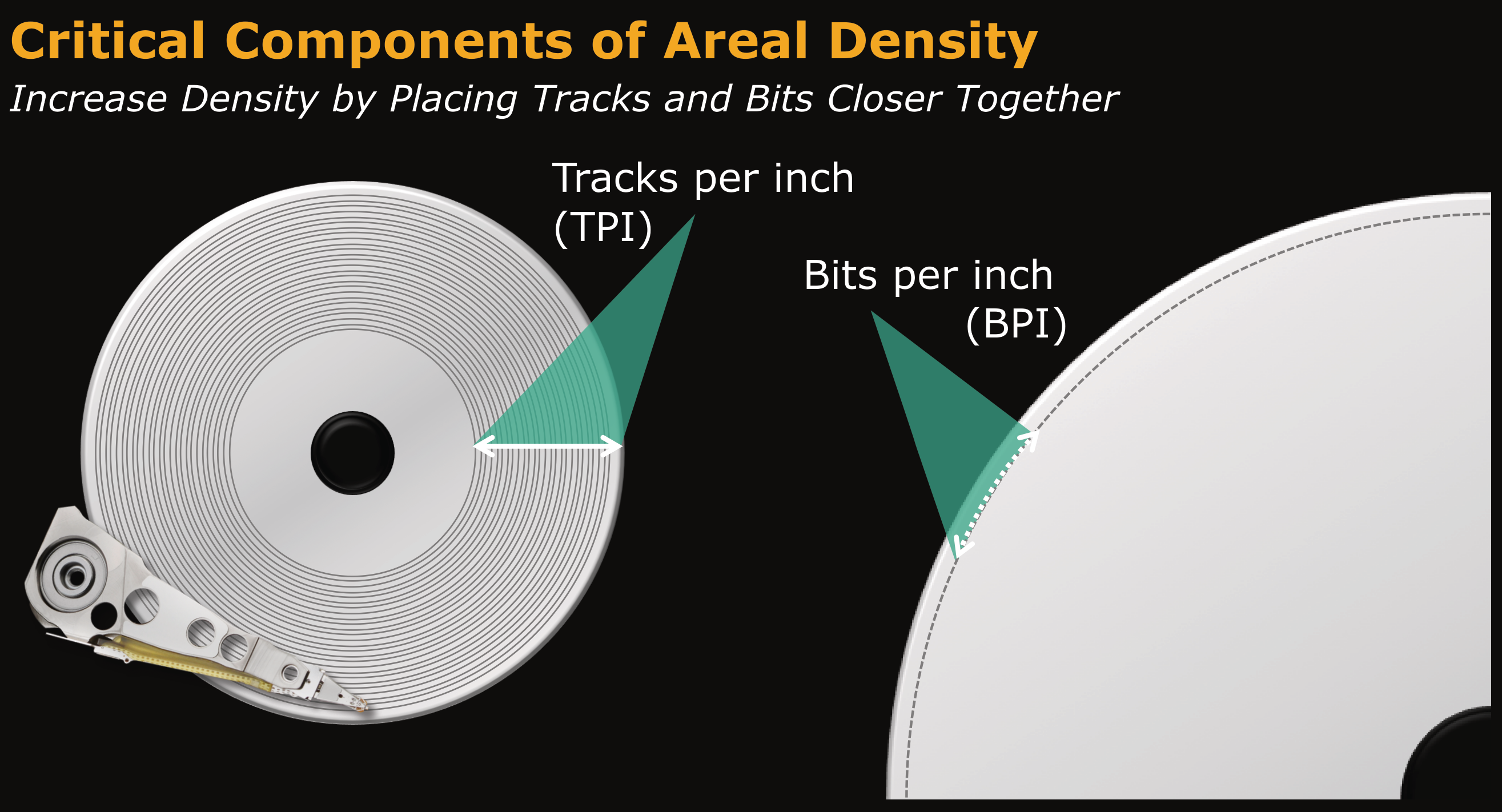
Hard drives in the early 2000s primarily relied on longitudinal recording, with the data bits aligned horizontally in relation to the spinning platter - this is shown in the first half of the image below. One of the first major advancements after the turn of the century was the introduction of perpendicular magnetic recording (PMR) in 2005.
At the time PMR made its breakthrough, Hitachi commissioned an amusing video called 'Get Perpendicular', which was used to demonstrate this technology and reaching 230 gigabits per square inch. The video can be found here.
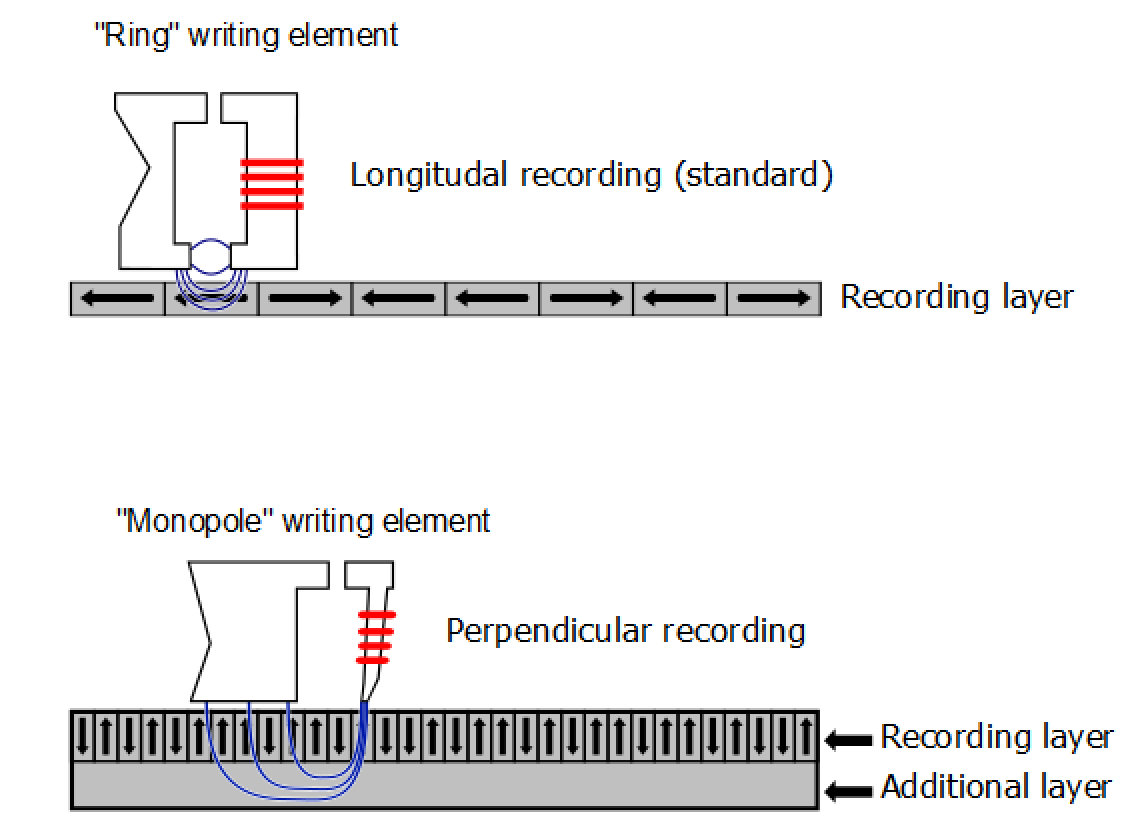
PMR was developed as a solution to the previous areal density limits of around 200 Gb/sq.in caused by the 'superparamagnetic effect' where the density of bits would cause the bits to flip magnetic orientation and corrupt data. PMR, by itself, can theoretically hit around 1.1 Tb/sq.in.
Alongside PMR, more technologies have come into play. The most recently launched hard drives (the Seagate 12TB ones) have an areal density of 923 Gb/sq.in. The industry came up with a number of solutions to keep increasing hard drive capacity while remaining within the theoretical areal density limits of PMR technology:
Helium-filled drives: One of the bottlenecks in modern drivers is the physical resistance on the heads by the air around the platters. Using helium reduces that resistance, albeit, with the requirement of sealed enclosures. The overall effect is improved head stability and a reduction in internal turbulence. This allows for a shorter distance between platters, giving manufacturers the ability to stack up to seven in a single 3.5" drive (rather than the usual six). Helium drives were first introduced to the market in 2012 by HGST. The latest helium drives come with as many as eight platters.
Shingled magnetic recording (SMR): In this technology, the track layouts are modified to give overlaps, similar to how roof shingles are laid (hence the name). While this creates challenges in rewriting over areas already containing data (the need to avoid overwriting valid data that has to be retained), there are sub-technologies and methods to mitigate some of these issues. The challenges can be either solved on the host side or the drive side. Seagate was the first to ship drive-managed SMR drives in 2013.
Improvements in actuator technology: In the last few years, Western Digital has been shipping 'micro actuators' that allow for finer positioning and control compared to traditional actuator arms. This directly translates to drives with a higher bit density.
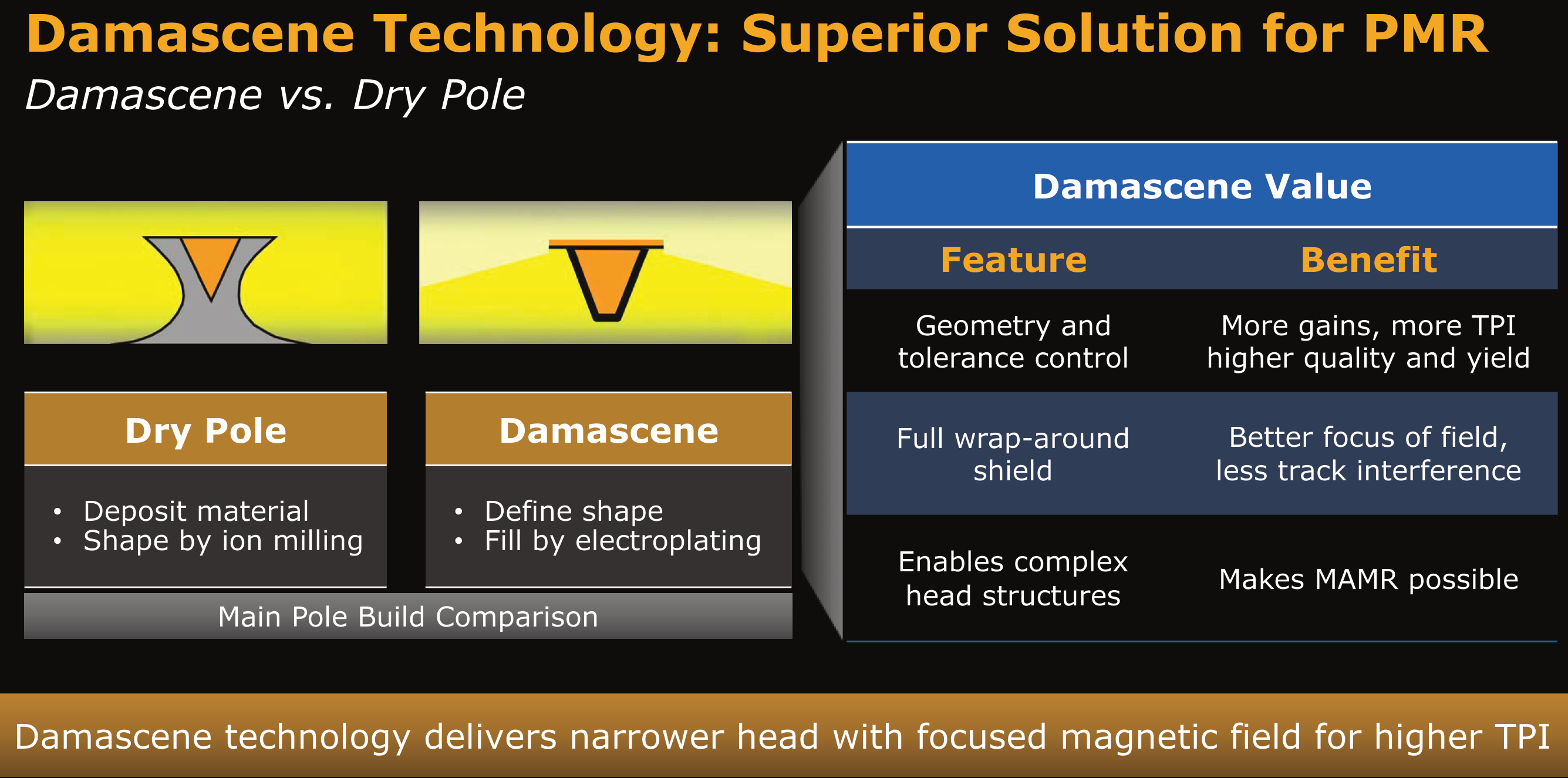
Improvements in head manufacturing: Traditionally, PMR heads have been manufactured using the Dry Pole process involving material deposition and ion milling. Recently, Western Digital has moved to the Damascene process (PDF) that involves a etched pattern filled using electroplating. This offered a host of advantages including a higher bit density.
We had briefly mentioned PMR technology having theoretical limits earlier in this section. Traditional PMR can deliver up to 1.1 Tb/sq.in. with improved actuators and heads. Use of SMR and TDMR (Two Dimensional Magnetic Recording) can drive this up to 1.4 Tb/sq.in.
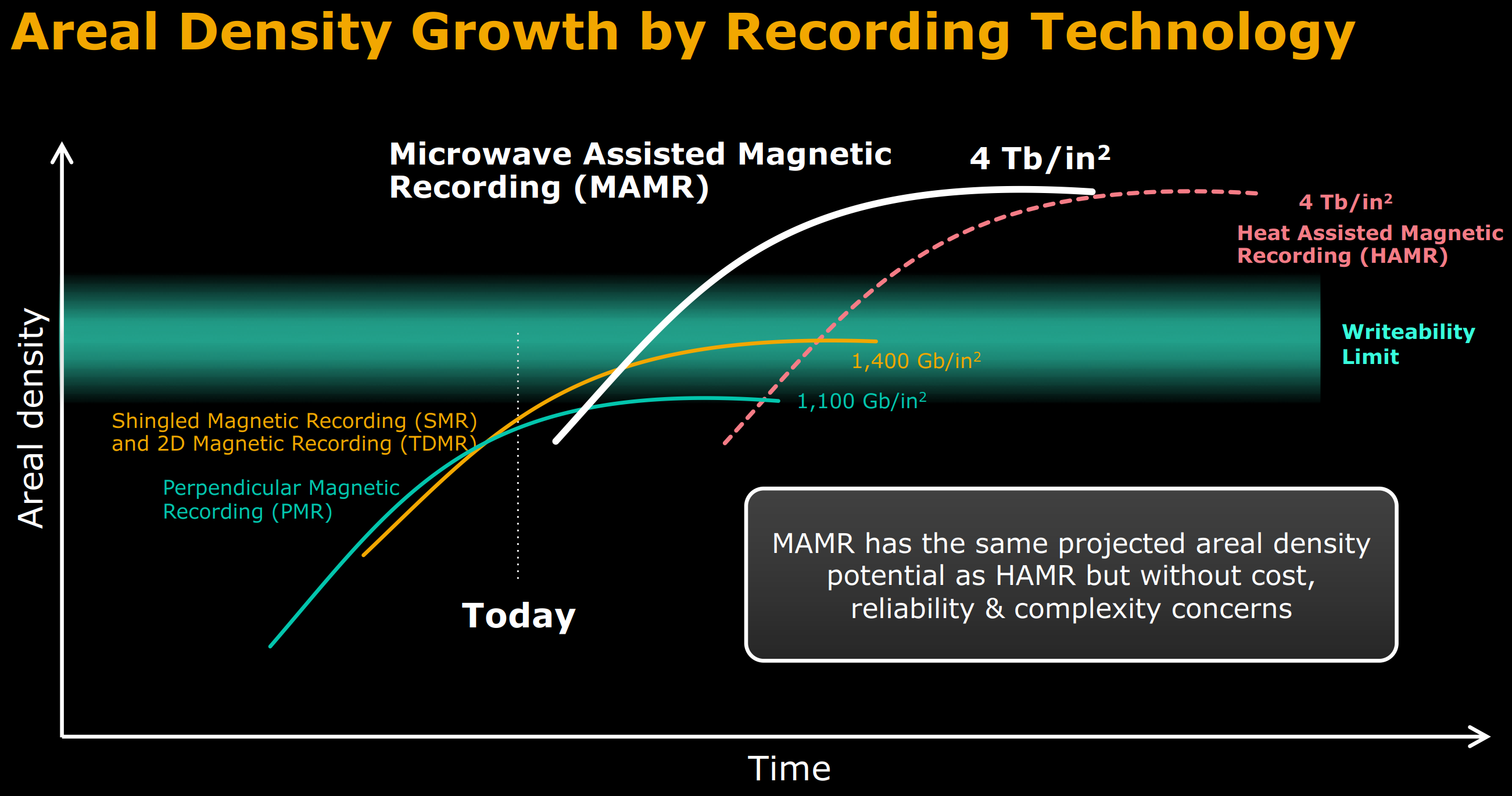
At those areal densities, the TPI and BPI need to be so high that the media grain pitch (the smallest size that the metallic elements that store individual bits can be) is around 7-8 nm. These small grains present a number of challenges, such as the head not being capable of creating a strong enough magnetic field for stable recording.
One solution to this would be to make it easier to write the data to the grain. Decreasing the resistance to magnetization (technically, lowering the coercivity), allows the head's field to modify the magnetic state of the grain. This requires extra energy, such as thermal energy, to be directly applied to the grain for the short amount of time that is needed to write a bit. This is the point where the 'energy-assist' aspect comes into the picture.
Over the last several years, a lot of focus has been on heat-assisted magnetic recording (HAMR), where the lowered resitance (coercivity) is achieved by locally heating the grains using a laser. This brings in a number of concerns that have prevented mass production of drives based on HAMR technology.

MAMR, on the other hand, uses microwaves to enable recording. A primary reason for MAMR not being considered as a viable technology by industry analysts so far was the complexity associated with designing a write head to include a microwave generator. In the next section, we take a look at how Western Digital was able to address this.








127 Comments
View All Comments
Jaybus - Monday, October 16, 2017 - link
1 gigabit Ethernet has an upper limit of 125 MB/s. It would take a minimum of 320,000 seconds or around 3.7 days of continuous 125 MB/s transfer rate to backup a 40 TB drive. Cloud backup of large volumes of data isn't going to be practical until at least 20 gigabit connections are commonplace.tuxRoller - Thursday, October 12, 2017 - link
Backing up to the cloud is really slow.Retrieving from the cloud is really slow.
When gigabit becomes ubiquitous then it will make more sense.
Even then, your should keep at least one copy of the data for data about offline and local.
Btw, I agree that raid is dead, but for different reasons. Namely, we've the much more flexible erasure coding (much more sophisticated than the simple xor encoding used by some of the raid levels) schemes that let you apply arbitrary amounts of redundancy and decide on placement of data. That's what the data centers have been moving towards.
alpha754293 - Thursday, October 12, 2017 - link
Even with Gb WAN, it'd still be slow.I have GbE LAN and I'm starting to run into bottlenecks with that being slow that once I have the funds to do so, I'm likely going to move over to 4x FDR IB.
tuxRoller - Thursday, October 12, 2017 - link
Slower than an all ssd, 10g lan, but how many people have that? 1g is roughly HDD speed.BurntMyBacon - Friday, October 13, 2017 - link
@tuxRoller1Gbps = 128MBps. cekim seems to think that 250MBps is a better estimate and alpha75493 suggests that these drives will increase in speed well beyond that. Granted this will not hold up for small file writes, but for large sequential data sets, the days of 1G ethernet being roughly equal to HDD speed are soon coming to an end.
tuxRoller - Friday, October 13, 2017 - link
Even now HDD have sequential (non-cached) speeds in excess of 300MB (for enterprise 15k drives), but 250MB+ is currently available with the 8TB+ 7200 drives.Those are best case, but they might also be readily achievable depending on how your backup software works (eg., a block-based object store vs NTFS/zfs/xfs/etc).
alpha754293 - Thursday, October 12, 2017 - link
@cekimYour math is a little bit off. If the areal density increases from 1.1 Tb/in^2 to 4 Tb/in^2, then so too will the data transfer speeds.
It has to.
Check that and update your calcs.
@imaheadcase
RAID is most definitely not dead.
RAID HBAs addressing SANs is still farrr more efficient to map (even with GPT) a logical array rather than lots of physical tables.
You do realise that there are rackmount enclosures that hold like 72 drives, right?
If that were hosted as a SAN (or iSCSI), there isn't anything that you can put as AICs that will allow a host to control 72 JBOD drives simultaneously.
It'd be insanity, not to mention the cabling nightmare.
bcronce - Thursday, October 12, 2017 - link
Here's an interest topic on raid rebuilds for ZFS. While it can't fix the issue of writing 250MiB/s to a many TiB storage device, it is fun.Parity Declustered RAID for ZFS (DRAID)
A quick overview is that ZFS can quickly rebuild a storage device if the storage device was mostly empty. This is because ZFS only needs to rebuild the data, not the entire drive. On the other hand, as the device gets fuller, the rate of a rebuild gets slower because walking the tree causes random IO. DRAID allows for a two pass where it optimistically writes out the data via a form of parity, then scrubs the data after to make sure it's actually correct. This allows the device to be quickly rebuilt by deferring the validation.
alpha754293 - Thursday, October 12, 2017 - link
My biggest issue with ZFS is that there are ZERO data recovery tools available for it. You can't do a bit read on the media in order to recover the data if the pool fails.I was a huge proponent of ZFS throughout the mid 2000s. Now, I am completely back to NTFS because at least if a NTFS array fails, I can do a bit-read on the media to try and recover the data.
(Actually spoke with the engineers who developed ZFS originally at Sun, now Oracle and they were able to confirm that there are no data recovery tools like that for ZFS. Their solution to a problem like that: restore from backup.)
(Except that in my case, the ZFS server was the backup.)
BurntMyBacon - Friday, October 13, 2017 - link
Are there any freely available tools to do this for NTFS. If so, please post as I'm sure more than an few people here would be interested in acquiring said tools. If not, what is your favorite non-free tool?I've been a huge fan of ZFS, particularly after my basement flooded and despite my NAS being submerged, I was able to recover every last bit of my data. Took a lot of work using DD and DDRescue, but I eventually got it done. That all said, a bit read tool would be nice.