Western Digital Stuns Storage Industry with MAMR Breakthrough for Next-Gen HDDs
by Ganesh T S on October 12, 2017 8:00 AM ESTScaling Hard Drive Capacities
Hard disk drives using magnetic recording have been around for 60+ years. Despite using the same underlying technology, the hard drives of today look nothing like the refrigerator-sized ones from the 1960s. The more interesting aspect in the story is the set of advancements that have happened since the turn of the century.
At a high level, hard disks are composed of circular magnetic plates or 'platters' on which data is recorded using magnetization and the patterns of magnetization represent the data stored. The patterns are laid out in terms of tracks. They are created, altered and recognized with the help of 'heads' mounted on an actuator that perform read and write operations. Modern hard disks have more than one platter in a stack, with each platter using its own individual 'head' to read and write.
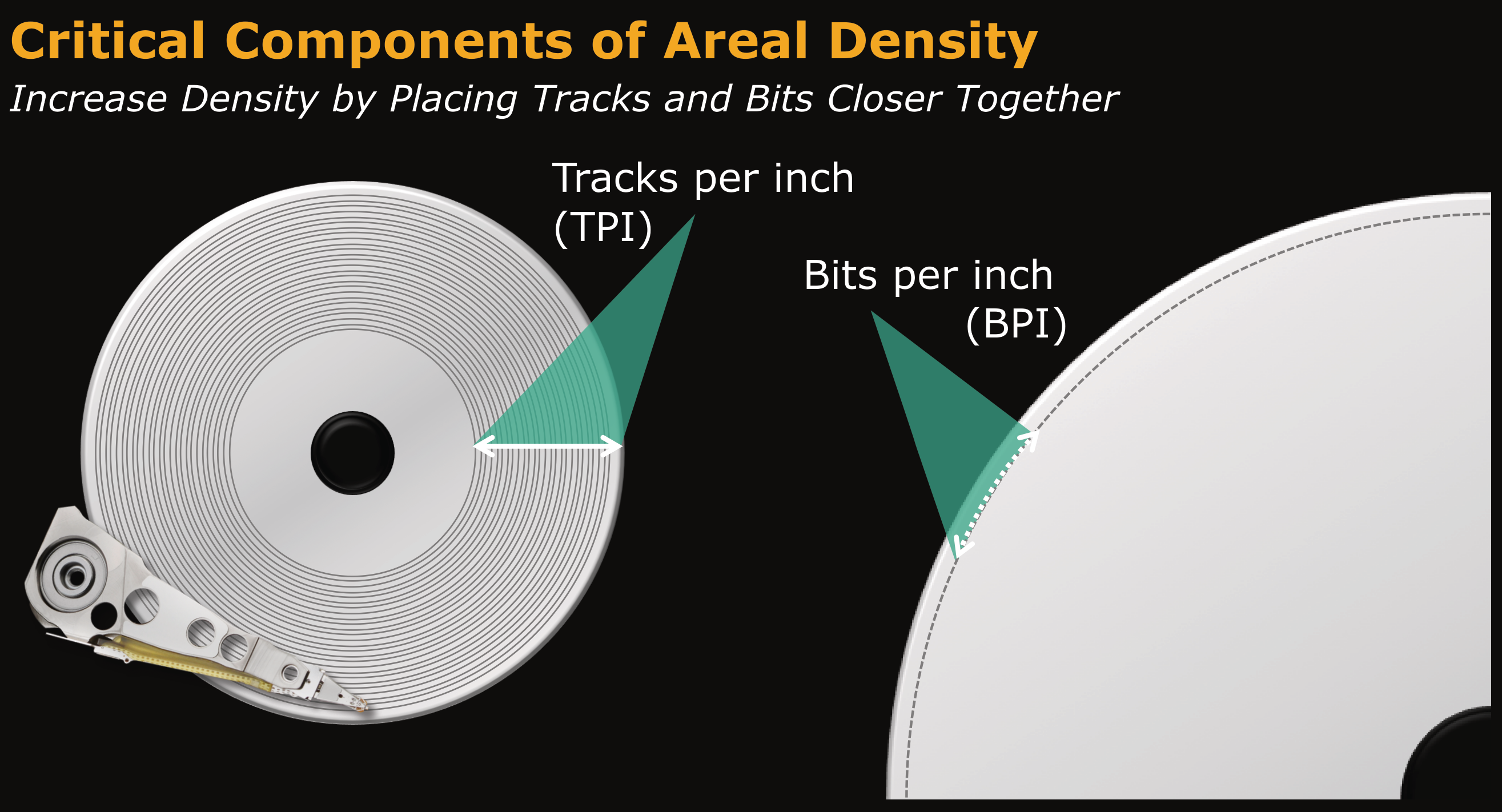
There are additional hardware components - the motor, spindle, and electronics. The segment of interest from a capacity perspective are the platters and the heads. The slide below shows two ways to increase the capacity of a platter - increasing the number of tracks per inch (TPI) and/or increasing the number of bits per inch (BPI) in a single track. Together they yield a metric for areal density, which the industry gives as a value in bits per square inch, such as gigabits per square inch (Gb/in2) or terabits per square inch (Tb/in2).
Hard drives in the early 2000s primarily relied on longitudinal recording, with the data bits aligned horizontally in relation to the spinning platter - this is shown in the first half of the image below. One of the first major advancements after the turn of the century was the introduction of perpendicular magnetic recording (PMR) in 2005.
At the time PMR made its breakthrough, Hitachi commissioned an amusing video called 'Get Perpendicular', which was used to demonstrate this technology and reaching 230 gigabits per square inch. The video can be found here.
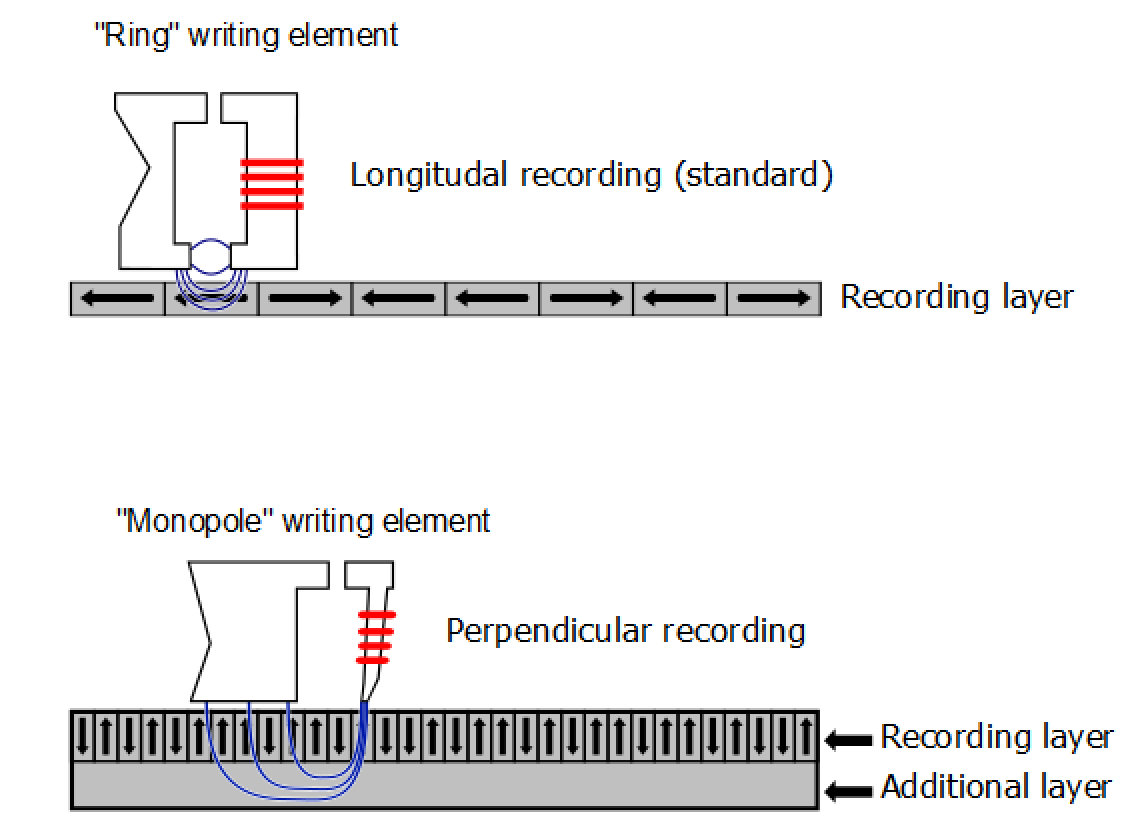
PMR was developed as a solution to the previous areal density limits of around 200 Gb/sq.in caused by the 'superparamagnetic effect' where the density of bits would cause the bits to flip magnetic orientation and corrupt data. PMR, by itself, can theoretically hit around 1.1 Tb/sq.in.
Alongside PMR, more technologies have come into play. The most recently launched hard drives (the Seagate 12TB ones) have an areal density of 923 Gb/sq.in. The industry came up with a number of solutions to keep increasing hard drive capacity while remaining within the theoretical areal density limits of PMR technology:
Helium-filled drives: One of the bottlenecks in modern drivers is the physical resistance on the heads by the air around the platters. Using helium reduces that resistance, albeit, with the requirement of sealed enclosures. The overall effect is improved head stability and a reduction in internal turbulence. This allows for a shorter distance between platters, giving manufacturers the ability to stack up to seven in a single 3.5" drive (rather than the usual six). Helium drives were first introduced to the market in 2012 by HGST. The latest helium drives come with as many as eight platters.
Shingled magnetic recording (SMR): In this technology, the track layouts are modified to give overlaps, similar to how roof shingles are laid (hence the name). While this creates challenges in rewriting over areas already containing data (the need to avoid overwriting valid data that has to be retained), there are sub-technologies and methods to mitigate some of these issues. The challenges can be either solved on the host side or the drive side. Seagate was the first to ship drive-managed SMR drives in 2013.
Improvements in actuator technology: In the last few years, Western Digital has been shipping 'micro actuators' that allow for finer positioning and control compared to traditional actuator arms. This directly translates to drives with a higher bit density.
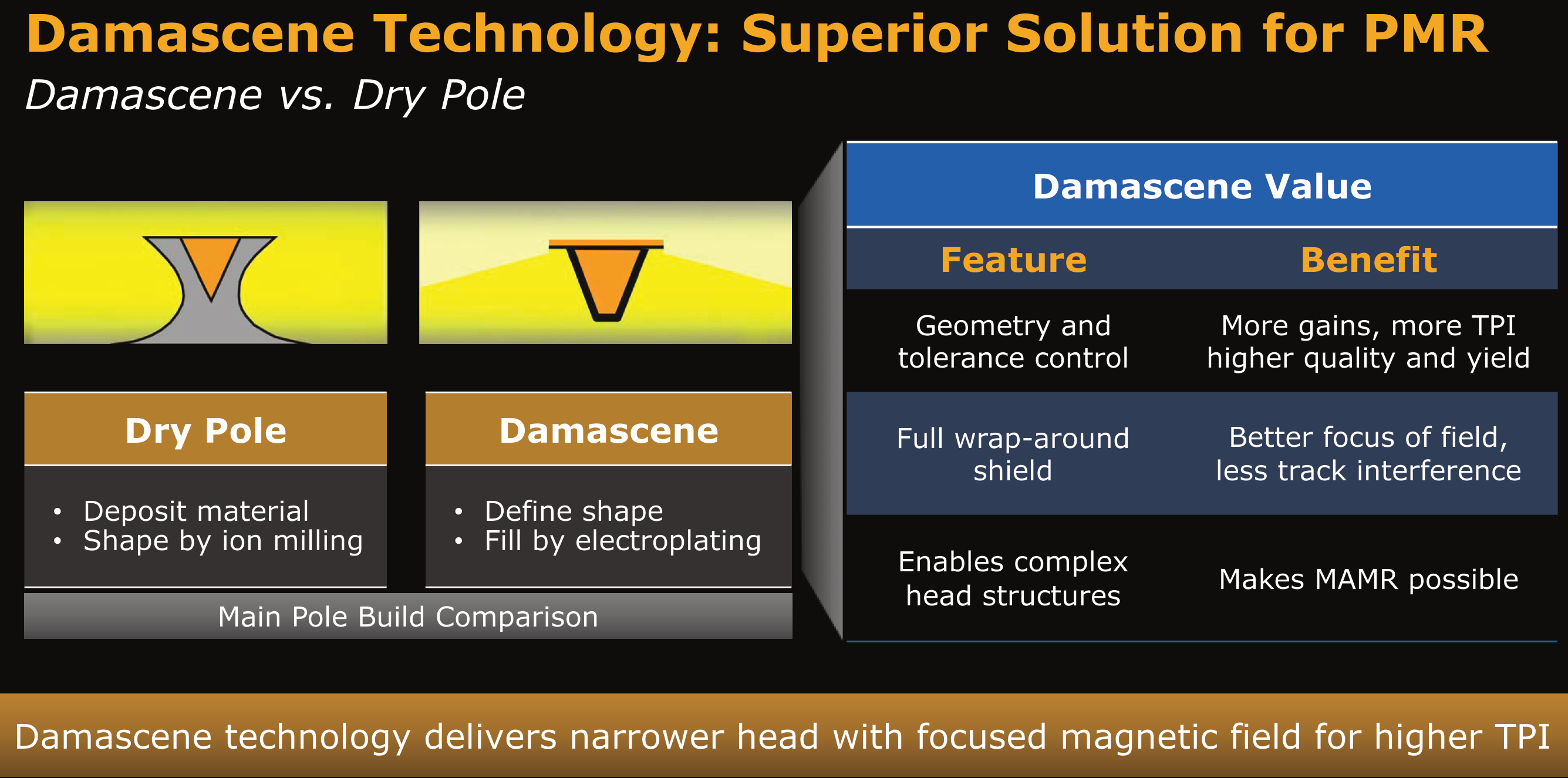
Improvements in head manufacturing: Traditionally, PMR heads have been manufactured using the Dry Pole process involving material deposition and ion milling. Recently, Western Digital has moved to the Damascene process (PDF) that involves a etched pattern filled using electroplating. This offered a host of advantages including a higher bit density.
We had briefly mentioned PMR technology having theoretical limits earlier in this section. Traditional PMR can deliver up to 1.1 Tb/sq.in. with improved actuators and heads. Use of SMR and TDMR (Two Dimensional Magnetic Recording) can drive this up to 1.4 Tb/sq.in.
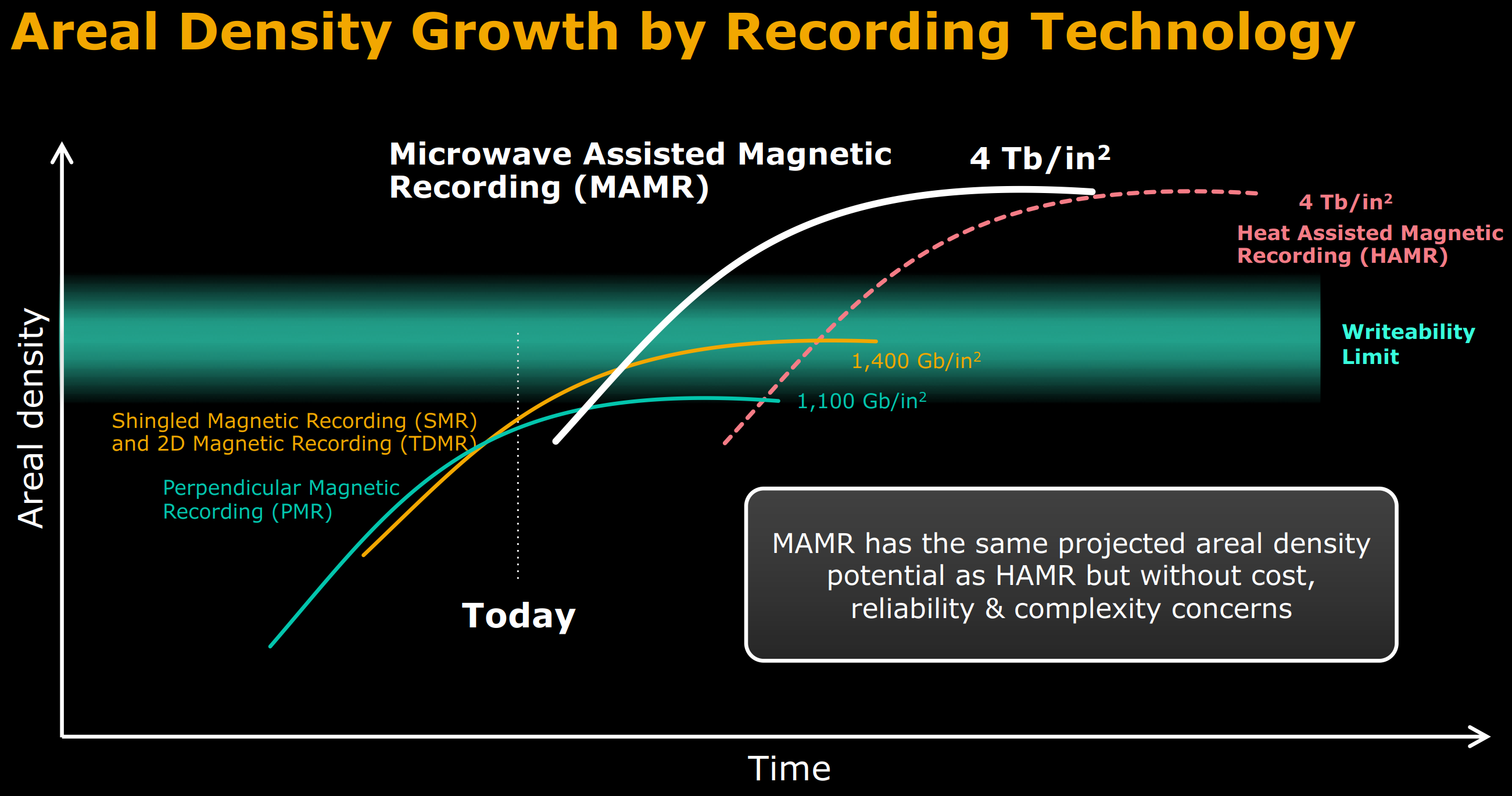
At those areal densities, the TPI and BPI need to be so high that the media grain pitch (the smallest size that the metallic elements that store individual bits can be) is around 7-8 nm. These small grains present a number of challenges, such as the head not being capable of creating a strong enough magnetic field for stable recording.
One solution to this would be to make it easier to write the data to the grain. Decreasing the resistance to magnetization (technically, lowering the coercivity), allows the head's field to modify the magnetic state of the grain. This requires extra energy, such as thermal energy, to be directly applied to the grain for the short amount of time that is needed to write a bit. This is the point where the 'energy-assist' aspect comes into the picture.
Over the last several years, a lot of focus has been on heat-assisted magnetic recording (HAMR), where the lowered resitance (coercivity) is achieved by locally heating the grains using a laser. This brings in a number of concerns that have prevented mass production of drives based on HAMR technology.

MAMR, on the other hand, uses microwaves to enable recording. A primary reason for MAMR not being considered as a viable technology by industry analysts so far was the complexity associated with designing a write head to include a microwave generator. In the next section, we take a look at how Western Digital was able to address this.








127 Comments
View All Comments
cekim - Thursday, October 12, 2017 - link
The bigger concern is throughput - if it takes the bulk of the MTBF of a drive to write then read it we are gonna have a bad time... quick math - maybe I goofed, but given 250MB/s and TB = 1024^4 that's 167,772s or 2796m or 46 hours to read the entire drive. Fun time waiting 2 days for a raid re-build...imaheadcase - Thursday, October 12, 2017 - link
If you are using this for home use, you should not be using raid anyways. Since you will had SSD on computer, and also if its a server bandwidth is not a concern since its on LAN. And backing up to cloud is what %99 of people do in that situation.RAID is dead for most part.
qap - Thursday, October 12, 2017 - link
It's dangerous not only for RAID, but also for that "cloud" you speak of and underlaying object storages. Typical object storage have 3 replicas. With 250MBps peak write/read speed you are not looking at two days to replicate all files. In reality it's more like two weeks to one month because you are handling lot of small files, transfer over LAN and in that case both read and write suffer. Over the course of several weeks there is too high probability of 3 random drives failing.We were considering 60TB SATA SSDs for our object storage, but it simply doesn't add up even in case of SSD-class read/write.
Especially if there is only single supplier of such drives, chance of synchronized failure of multiple drives is too high (we had one such scare).
LurkingSince97 - Friday, October 20, 2017 - link
That is not how it works. If you have 3 replicas, and one drive dies, then all of that drive's data has two other replicas.Those two other replicas are _NOT_ just on two other drives. A large clustered file system will have the data split into blocks, and blocks randomly assigned to other drives. So if you have 300 drives in a cluster, a replica factor of 3, and one drive dies, then that drive's data has two copies, evenly spread out over the other 299 drives. If those are spread out across 30 nodes (each with 10 drives) with 10gbit network, then we have aggregate ~8000 MB/sec copying capacity, or close to a half TB per minute. That is a little over an hour to get the replication factor back to 3, assuming no transfers are local, and all goes over the network.
And that is a small cluster. A real one would have closer to 100 nodes and 1000 drives, and higher aggregate network throughput, with more intelligent block distribution. The real world result is that on today's drives it can take less than 5 minutes to re-replicate a failed drive. Even with 40TB drives, sub 30 minute times would be achievable.
bcronce - Thursday, October 12, 2017 - link
RAID isn't dead. The same people who used it in the past are still using it. It was never popular outside of enterprise/enthusiast use. I need a place to store all of my 4K videos.wumpus - Thursday, October 12, 2017 - link
[non-0] RAID almost never made sense for home use (although there was a brief point before SSDs where it was cool to partitions two drives so /home could be mirrored and /everything_else could be striped.Backblaze uses some pretty serious RAID, and I'd expect that all serious datacenters use similar tricks. Redundancy is the heart of storage reliability (SSDs and more old fashioned drives have all sorts of redundancy built in) and there is always the benefit of having somebody swap out the actual hardware (which will always be easier with RAID).
RAID isn't going anywhere for the big boys, but unless you have a data hording hobby (and tons of terrabytes to go with it), you probably don't want RAID at home. If you do, then you you will probably on need to RAID your backups (RAID on your primary only helps for high availability).
alpha754293 - Thursday, October 12, 2017 - link
I can see people using RAID at home thinking that it will give them the misguided latency advantage (when they think about "speed").(i.e. higher MB/s != lower latency, which is what gamers probably actually want when they put two SSDs on RAID0)
surt - Sunday, October 15, 2017 - link
Not sure what game you are playing, but at least 90% of the tier 1 games out there care mostly about throughput not latency when it comes to hard drive speed. Hard drive latency in general is too great for any reasonable game design to assume anything other than a streaming architecture.Ahnilated - Thursday, October 12, 2017 - link
Sorry but if you backup to the cloud you are a fool. All your data is freely accessible to anyone from the script kiddies on up. Much less transferring it over the web is a huge risk.Notmyusualid - Thursday, October 12, 2017 - link
@ AhnilatedI never liked the term 'script kiddies'.
What is the alternative? Waste your time / bust your ass writing your own exploit(s) - when so many cool exploits already exist?
Some of us who dabble with said scripts, have significant other networking / Linux knowledge, so it doesn't fit to denigrate us, just because we can't be arsed to write new exploits ourselves.
We've better things to be doing with our time...
I bet you don't make your own clothes, even though you possibly can.