The AMD Ryzen 5 1600X vs Core i5 Review: Twelve Threads vs Four at $250
by Ian Cutress on April 11, 2017 9:00 AM ESTRyzen 5, Core Allocation, and Power
In our original review of Ryzen 7, we showed that the underlying silicon design of the Ryzen package consists of a single eight-core Zeppelin die with Zen microarchitecture cores.
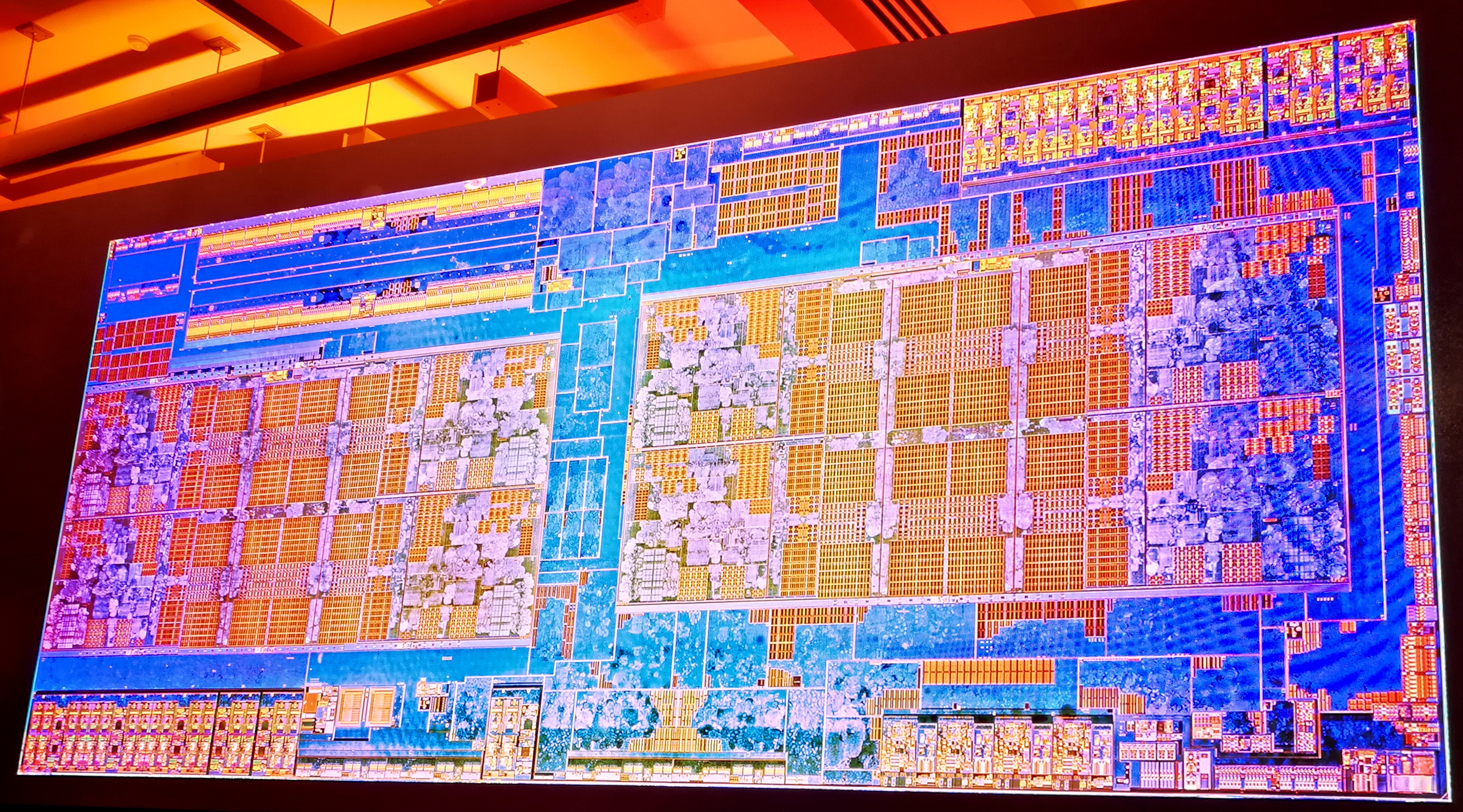
The silicon design consists of two core complexes (CCX) of four cores apiece. Each CCX comes with 512 KB of L2 cache per core, which is disabled when a core is disabled, and each CCX has 8MB of L3 cache which can remain enabled even when cores are disabled. This L3 cache is an exclusive victim cache, meaning that it only accepts evicted L2 cache entries, rather than loading data straight into it (which is how Intel builds their current L3 cache designs).
One of the suggestions regarding Ryzen 7’s performance was about thread migration and scheduling on the core design, especially as core-to-core latency varies depending on where the cores are located (and there’s a jump between CCXes). Despite the use of AMD’s new Infinity Fabric, which is ultimately a superset of HyperTransport, there is still a slightly longer delay jumping over that CCX boundary, although the default Windows scheduler knows how to manage that boundary as demonstrated by Allyn at PCPerspective.

So when dealing with a four-core or six-core CPU, and the base core design has eight-cores, how does AMD cut them up? It is possible for AMD to offer a 4+0, 3+1 or 2+2 design for its quad-core parts, or 4+2 and 3+3 variants for its hexacore parts, similar to the way that Intel cuts up its integrated graphics for GT1 variants.
There are some positives and negatives to each configuration, some of which we have managed to view through this review. The main downside from high level to a configuration split across CCXes, such as a 2+2 or 3+3, is that CCX boundary. Given that the Windows scheduler knows how to deal with this means this is less of an issue, but it is still present.
There are a couple of upsides. Firstly is related to binning – if the 2+2 chips didn’t exist, and AMD only supported 4+0 configurations, then if the binning of such processors was down to silicon defects, fewer silicon dies would be able to be used, as one CCX would have to be perfect. Depending on yield this may or may not be an issue to begin with, but having a 2+2 (and AMD states that all 2+2 configs will be performance equivalent) means more silicon available, driving down cost by having more viable CPUs per wafer out of the fabs.
Secondly, there’s the power argument. Logic inside a processor expends energy, and more energy when using a higher voltage/frequency. When placing lots of high-energy logic next to each other, the behavior becomes erratic and the logic has to reduce in voltage/frequency to remain stable. This is why AVX/AVX2 from Intel causes those cores to run at a lower frequency compared to the rest of the core. A similar thing can occur within a CCX: if all four cores of a CCX are loaded (and going by Windows Scheduler that is what happens in order), then the power available to each core has to be reduced to remain stable. Ideally, if there’s no cross communication between threads, you want the computation to be in opposite cores as threads increase. This is not a new concept – some core designs intentionally put in ‘dark silicon’ - silicon of no use apart from providing extra space/area between high power consuming logic. By placing the cores in a 2+2 and 3+3 design for Ryzen 5, this allows the cores to run at a higher power than if they were in 4+0 and 4+2 configurations.
Here’s some power numbers to show this. First, let’s start with a core diagram.
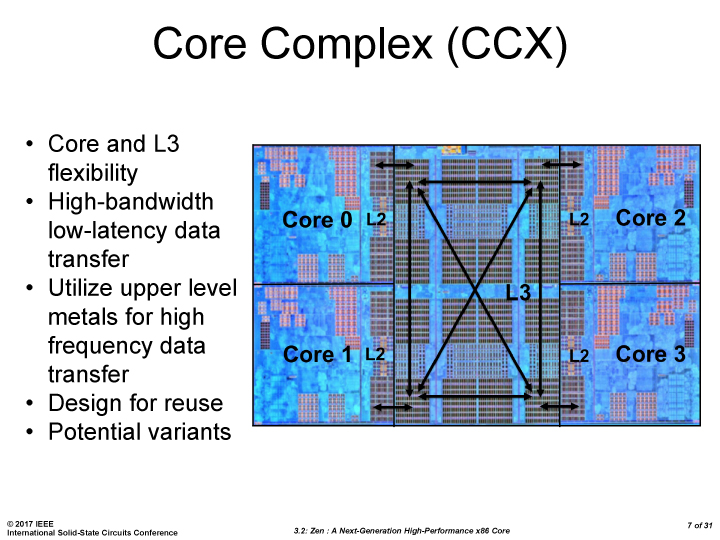
Where exactly the 0/1/2/3 cores are labelled is not really important, except 0-3 are in one CCX and 4-7 are in another CCX. As we load up the cores with two threads each, we can see the power allocation change between them. It is worth noting that the Ryzen cores have a realistic voltage/frequency limit near 4.0-4.1 GHz due to the manufacturing process – getting near or above this frequency requires a lot of voltage, which translates into power.
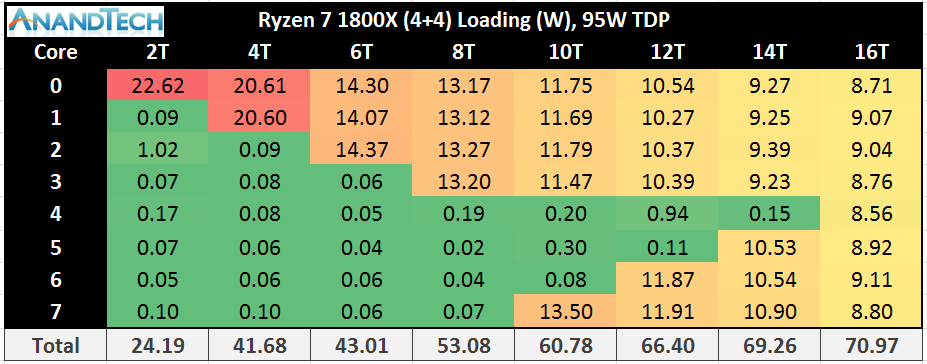
First up is the 1800X, which is a 4+4 configuration with a maximum TDP of 95W. One fully loaded core gets 22.6W, and represents the core at its maximum frequency with XFR also enabled. The same thing happens with two cores fully loaded, but at 20.6 W apiece. Moving onto three cores loaded is where XFR is disabled, and we see the drop to 3.7 GHz is saving power, as we only consume +1.33W compared to the two cores loaded situation. Three to four cores, still all on the same CCX, shows a decrease in power per core.
As we load up the first core of the second CCX, we see an interesting change. The core on CCX-2 has a bigger power allocation than any core in CCX-1. This can be interpreted in two ways: there is more dark silicon around, leading to a higher potential for this core on CCX-2, or that more power is required given the core is on its own. Technically it is still running at the same frequency as the cores on CCX1. Now as we populate the cores on CCX-2, they still consume more power per core until we hit the situation where all cores are loaded and the system is more or less equal.
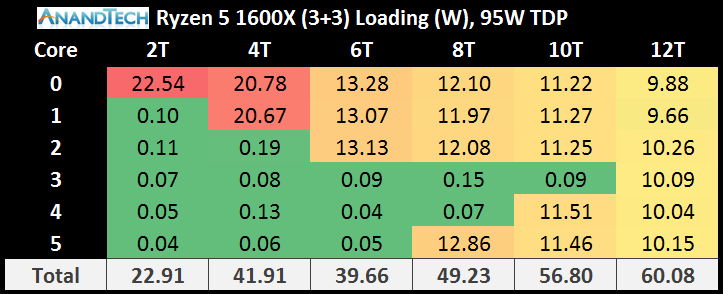
Moving to the Ryzen 5 1600X, which is a 3+3 configuration, nets more of the same. During XFR with one or two cores loaded, the power consumption is high. As we move onto the second CCX, the cores on CCX-2 consumer more power per core than those already loaded on CCX-1.
It is worth noting here that the jump from two cores loaded to three cores loaded on the 3+3 gives a drop in the total power consumption of the cores. Checking my raw data numbers, and this also translates to a total package power drop as well, showing how much extra effort it is to run these cores near 4.0 GHz with XFR enabled.
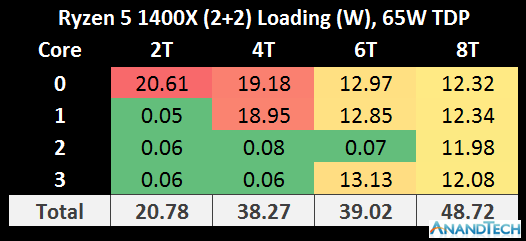
On the Ryzen 5 1500X, using a 2+2 configuration, the situation is again duplicated. The hard comparison here is the 2+2 of the 1500X to the 4+0 on the 1800X, because the TDP of each of the processors is different.
It should be noted however the total package power consumption (cores plus IO plus memory controller and so on) is actually another 10W or so above these numbers per chip.
The cache configurations play an important role in the power consumption numbers as well. In a 3+3 or a 2+2 configuration, despite one or two cores per CCX being disabled, the L3 cache is still fully enabled in these processors. As a result, cutting 25% of the cores doesn’t cut 25% of the total core power, depending on how the L3 cache is being used.
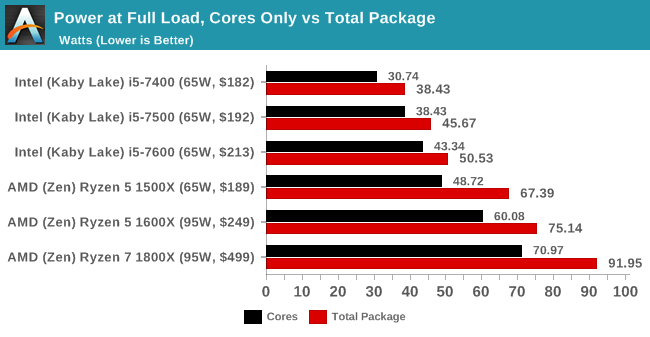
Nonetheless, the Ryzen 5 1600X, despite being at the same rated TDP as the Ryzen 7 1800X, does not get close to matching the power consumption. This ropes back into the point at the top of the page – usually we see fewer cores giving a higher frequency to match the power consumption with parts that have more cores. Because the silicon design has such a high barrier to get over 4.0 GHz with voltage and power, AMD has decided that it is too big a jump to remain stable, but still given the 1600X the higher TDP rating anyway. This may be a nod to the fact that it will cause users to go out and buy bigger cooling solutions, providing sufficient headroom for Turbo modes and XFR, giving better performance.
Despite this, we see the 1800X and 1500X each tear their TDP rating for power consumption (92W vs 95W and 67W vs 65W respectively).
However, enough talking about the power consumption. Time for benchmarks!








254 Comments
View All Comments
Phiro69 - Tuesday, April 11, 2017 - link
Thank you Ian!Maybe at some point as part of your benchmark description you have a url to a page showing basic (e.g. exactly the level of information you provided above but not step by step hand holding) benchmark setup instructions. I know I wonder if I've configured my builds correctly when I put together new systems; I buy the parts based on benchmarks but I don't ever really validate they perform at that level/I have things set correctly.
qupada - Tuesday, April 11, 2017 - link
I was curious about this too. Obviously a direct comparison between your Windows test and my Linux one is going to be largely meaningless but I felt the need to try anyway. Since Linux is all I have, this is what we get.My Haswell-EP Xeon E5-1660v3 - approximately an i7-5960X with ECC RAM, and that CPU seems to be oft-compared to the 1800X you have put in your results - clocks in at 78:36 to compile Chromium (59.0.3063.4), or 18.31 compiles per day (hoorah for the pile of extra money I spent on it resulting in such a small performance margin). However that's for the entire process, from unpacking the tarball, compiling, then tarring and compressing the compiled result. My machine is running Gentoo, it was 'time emerge -OB chromium' (I didn't feel like doing it manually to get just the compile). Am I reading right you've used the result of timing the 'ninja' compile step only?
I only ask because there definitely could be other factors in play for this one - for the uninitiated reading this comment, Chromium is a fairly massive piece of software, the source tar.xz file for the version I tried is 496MB (decompressing to 2757MB), containing around 28,000 directories and a shade under 210,000 files. At that scale, filesystem cache is definitely going to come into play, I would probably expect a slightly different result for a freshly rebooted machine versus one where the compile was timed immediately after unpacking the source code and it was still in RAM (obviously less of a difference on an SSD, but probably still not none).
It is an interesting test metric though, and again I haven't done this on WIndows, but there is a chunk in the middle of the process that seems to be single-threaded on a Linux compile (probably around 10% of the total wall clock time), so it is actually quite nice that it will benefit from both multi-core and single-core performance and boost clocks.
Also with a heavily multi-threaded process of that sort of duration, probably a great test of how long you get before thermal throttling starts to hurt you. I have to admit I'm cheating a bit by watercooling mine (not overclocked though) so it'll happily run 3.3GHz on a base clock of 3.0 across all eight cores for hours on end at around ~45°C/115°F.
rarson - Tuesday, April 11, 2017 - link
14393.969 was released March 20th, any reason you didn't use that build?Ian Cutress - Friday, April 14, 2017 - link
Because my OS is already locked down for the next 12-18 months of testing.Konobi - Tuesday, April 11, 2017 - link
I don't know what's up with those FPS number in rocket league 1080p. I have ye olde FX-8350 @ 4.8GHz and a GTX 1070 @ 2.1GHz and I get 244fps max and 230FPS average at 1080p Ultra.Ian Cutress - Tuesday, April 11, 2017 - link
I'm running a 4x4 bot match on Aquadome. Automated inputs to mimic gameplay and camera switching / tricks, FRAPS over 4 minutes of a match.jfmonty2 - Wednesday, April 12, 2017 - link
Why Aquadome specifically? It's been criticized for performance issues compared to most of the other maps in the game, although the most recent update has improved that.Ian Cutress - Friday, April 14, 2017 - link
On the basis that it's the most strenuous map to test on. Lowest common denominator and all that.Adam Saint - Tuesday, April 11, 2017 - link
"Looking at the results, it’s hard to notice the effect that 12 threads has on multithreaded CPU tests"Perhaps you mean *not* hard to notice? :)
coder543 - Tuesday, April 11, 2017 - link
I agree. That was also confusing.