Intel Confirms 8th Gen Core on 14nm, Data Center First to New Nodes
by Ian Cutress on February 9, 2017 6:52 PM EST- Posted in
- CPUs
- Intel
- Core 8th Gen
- Cannon Lake

A quick news piece on information coming out of Intel’s annual Investor Day in California. As confirmed to Ashraf Eassa by Intel at the event, Intel’s 8th Generation Core microarchitecture will remain on the 14nm node. This is an interesting development with the recent launch of Intel’s 7th Generation Core products being touted as the ‘optimization’ behind the new ‘Process-Architecture-Optimization’ three-stage cadence that had replaced the old ‘tick-tock’ cadence. With Intel stringing out 14nm (or at least, an improved variant of 14nm as we’ve seen on 7th Gen) for another generation, it makes us wonder where exactly Intel can promise future performance or efficiency gains on the design unless they start implementing microarchitecture changes.
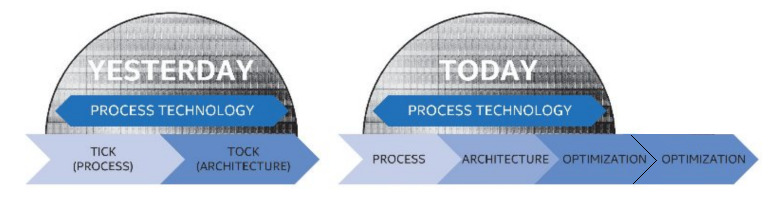
Despite this, if you were to believe supposed ‘leaked’ roadmaps (which we haven’t confirmed from a second source as of yet), the 8th Generation product ‘Cannon Lake’ is more geared towards the Y and U part of Intel’s roadmap. This would ring true with a mobile first strategy that Intel has mirrored with recent generations such that the smaller, low power chips are off the production line for a new product first, however we'd also expect 10nm to also be in the smaller chips first too (as demonstrated at CES). Where Cannon Lake will end up in the desktop or enterprise segment however remains to be seen. To put something a bit more solid into this, Ashraf also mentioned words from Dr. Venkata ‘Murthy’ Renduchintala, VP and GM of Client and IoT:
‘Murthy referred to it at the event, process tech use will be ‘fluid’ based on segment’.
If one read too much into this, we may start seeing a blend of process nodes for different segments at the same time for different areas of the market. We already do have that to some extent with the mainstream CPUs and the HEDT/Xeon families, but this phrasing seems that we might get another split between consumer products or consumer and enterprise. We may get to a point where Intel's 'Gen' naming scheme for its CPUs covers two or more process node variants.
Speaking of the Enterprise segment, another bit of information has also surfaced, coming from a slide during a talk by Diane Bryant (EVP/GM of Data Center) and posted online by Ashraf. The slide contains the words ‘Data center first for next process node’

We can either talk about process node in terms of the ‘number’, either 14nm/10nm/7nm, or by variants within that process (high power, high efficiency). One might suspect that this means Intel is moving hard and fast with 10nm for Xeons and big computing projects, despite showing off 10nm silicon at CES earlier this year. That being said, it’s important to remember that the data center market is large, and includes high-density systems with many cores, such as Atom cores, and Intel did recently open up its 10nm foundry business to ARM Artisan IP projects. So while the slide does say ‘Data center first’, it might be referring to DC projects based on ARM IP in that segment rather than big 4-24+ core Xeons. At this stage of the game it is hard to tell.
On top of all this, Intel still has extreme confidence in its foundry business. An image posted by Dick James of Siliconics from the livestream shows Intel expects to have a three-year process node advantage when its competitors (Samsung, TSMC) start launching 10nm:

I’ve been brief with this news for a reason - at this point there are a lot of balls in the air with many different ways to take this information, and the Investor Day is winding down on talks and finishing with smaller 1-on-1 meetings. We may get further clarification on this news as the day goes on.
Update 1: On speaking with Diane Bryant, the 'data center gets new nodes first' is going to be achieved by using multiple small dies on a single package. But rather than use a multi-chip package as in previous multi-core products, Intel will be using EMIB as demonstrated at ISSCC: an MCP/2.5D interposer-like design with an Embedded Multi-Die Interconnect Bridge (EMIB).
An Intel Slide from ISSCC, via PC Watch
Initially EMIB was thought of as a technology relating to Intel's acquisition of Altera and potential future embedded FPGA designs, and given the slide above and comments made at the Investor Day, it seems there are other plans for this technology too. The benefit of using multiple smaller dies over a large monolithic 600mm2 die is typically related to cost and yield, however the EMIB technology also has to be up to par and there may be a latency or compatibility trade-off.
Source: Intel, @TMFChipFool








124 Comments
View All Comments
name99 - Friday, February 10, 2017 - link
What do those points have to do with my criticism? My complaint, and the comment, was with "their fake 7nm process will be a boutique low yields one that only Apple will want (if ever want it)."The subsequent statements are just as indefensible. We have NO IDEA what the yields are for these processes, so no-one outside the foundries is in a position to make claims like "all these foundries avoid to manufacture big dies under sub 14nm processes and GPUs will stay on 16nm for a lot"
Might be true, might not, who knows? Even if the GPUs stay at 14/16nm for a while, that may have nothing to do with yield (and so die size) and may reflect the cost of masks vs expected sales.
ssj4Gogeta - Thursday, February 9, 2017 - link
"Process-architecture-optimization" seemed like something conjured up by the marketing department from the beginning, especially considering the marginal gains with Kaby Lake.lilmoe - Friday, February 10, 2017 - link
What gains? FF blocks that were available on Snapdragon and Exynos chips for years? lolclose - Friday, February 10, 2017 - link
It actually looked like something conjured up by the marketing department on the spot when they were left with no options. The marketing had it easy at Intel before. Engineering always delivered, there was no competition, life was great.All of a sudden engineering stopped delivering (for whatever reasons), competition started flaring up at least in leaked slides and teasers, and Intel's marketing department had a job to do for the first time in years. You can see for yourself how bad the lack of practice was...
jimjamjamie - Friday, February 10, 2017 - link
Now it's Process-Optimisation-Optimisation-Persistencenemoshotyany - Friday, February 10, 2017 - link
So their strategy is now POOP?shabby - Friday, February 10, 2017 - link
It was always poop to begin with.bcronce - Friday, February 10, 2017 - link
Intel spend 2.5x more on R&D than AMD's gross revenue. It's not like they're suddenly cutting their R&D, they just need to shift what they spend their money on. There's also hope for async CPUs. Intel has said in the past that die shrinks are so much easier and faster than making async CPUs. Maybe we'll start to see 10ghz+ CPUs in the future.Nagorak - Sunday, February 12, 2017 - link
There are diminishing returns. Also, AMD doesn't have to pay for newer fab technology, that falls on Global Foundries. Granted, in the past when GF struggled they were hobbled by it as well. But the point is, you can't compare Intel R&D directly to AMD's because a lot of Intel R&D is on process, and that R&D should be compared to GF.Nexing - Thursday, February 9, 2017 - link
"it makes us wonder where exactly Intel can promise future performance or efficiency gains on the design unless they start implementing microarchitecture changes."Just replacing bad Tim on the die for soldered CPUs will return them above average yearly thermal efficiency gains.